SEARCH
検索詳細
小澤 誠一数理・データサイエンスセンター教授
プロフィール
1989年神戸大学大学院工学研究科修士課程修了後、1998年に博士(工学)取得、2000年から神戸大学准教授、2011年より同教授。現在、神戸大学数理・データサイエンスセンター・センター長、大学院工学研究科電気電子工学専攻、未来医工学研究開発センターの教授を兼任し、2022年5月に株式会社テラアクソンを設立。修士学生のときにニューラルネットワークと出会い、以来35年以上にわたって、人工知能一筋で研究をしている。主に非定常環境における概念の継続学習、追加学習、知識移転、環境変動検出などの研究に従事し、最近は実環境で使えるAIを目指して、AI for Security / Security for AI、プライバシー保護データ解析、組織間連合学習の技術開発および応用を行っている。学会活動も活発に行っており、現在、International Neural Network Society 副会長、Asia Pacific Neural Network Society 前会長、システム制御情報学会 副会長、IEEE Transaction on Cyberneticsなどの英文誌編集員や国際会議など各種Chairを歴任してきた。AIの社会実装が真の意味で実現される世の中を目指して、日夜励んでいる。
研究者基本情報
■ 学位■ 研究ニュース
■ 授業科目
■ 研究キーワード
■ 研究分野
■ 委員歴
- 2023年12月 - 現在, The 31th International Conference on Neural Information Processing (ICONIP2024), Honorary Chair
- 2023年06月 - 現在, システム制御情報学会, 副会長
- 2021年06月 - 現在, IEEE World Congress on Computational Intelligence (WCCI) 2024, Financial Chair / IJCNN Technical Co-Chair
- 2019年01月 - 現在, International Neural Network Society (INNS), Vice-President
- 2017年01月 - 現在, IEEE CIS Smart World Technical Committee, Member
- 2017年01月 - 現在, IEEE Trans on Cybernetics, Associate Editor
- 2012年07月 - 現在, Pattern Analysis and Applications (Springer), Associate Editor
- 2010年01月 - 現在, IEEE CIS Neural Networks Technical Committee (NNTC), Member
- 2009年09月 - 現在, Evolving Systems (Springer), Editorial Board Member
- 2023年01月 - 2023年12月, Asia Pacific Neural Network Society (APNNS), Immedate Past President
- 2022年12月 - 2023年11月, The 30th International Conference on Neural Information Processing (ICONIP2023), Advisory Chair
- 2021年06月 - 2023年05月, システム制御情報学会, 理事(企画担当)
- 2021年03月 - 2023年02月, 日本神経回路学会, 副会長
- 2022年04月 - 2022年12月, The 29th International Conference on Neural Information Processing (ICONIP 2022), General Co-Chair
- 2022年01月 - 2022年12月, Artificial Intelligence and Cloud Computing Conference (AICCC 2022), General Co-Chair
- 2021年01月 - 2022年12月, Asia Pacific Neural Network Society (APNNS), President
- 2018年01月 - 2022年12月, IEEE Trans on Neural Networks and Learning Systems, Associate Editor
- 2020年09月 - 2021年07月, International Conference on Neural Networks (IJCNN) 2021, Program Co-Chairs
- 2020年06月 - 2021年05月, システム制御情報学会, 理事(庶務担当)
研究活動情報
■ 受賞- 2023年10月 情報処理学会, CSS2023奨励賞, 大規模言語モデルによるセキュリティ対策の視覚認知メカニズムのモデル化に向けた検討
- 2022年10月 情報処理学会, CSEC優秀研究賞, 機械学習を用いた悪性TLS通信の検知と通信特徴の推移に関する考察
- 2020年10月 情報処理学会, CSS2020コンセプト研究賞, ポート番号埋め込みベクトルを用いたダークネットスキャンパケット解析
- 2019年12月 Asia Pacific Neural Network Society, APNNS Excellent Service Award
- 2011年04月 IEEE Computational Intelligence Society, EAIS 2011 Outstanding Paper Award, "Incremental Recursive Fisher Linear Discriminant for Online Feature Extraction"に関する研究
- 2025年05月, Applied Sciences研究論文(学術雑誌)
- PURPOSE: Surgeons' adaptability to robotic manipulation remains underexplored. This study evaluated the participants' first-touch robotic training skills using the hinotori surgical robot system and its simulator (hi-Sim) to assess adaptability. METHODS: We enrolled 11 robotic surgeons (RS), 13 laparoscopic surgeons (LS), and 15 novices (N). After tutorial and training, participants performed pegboard tasks, camera and clutch operations, energizing operations, and suture sponge tasks on hi-Sim. They also completed a suture ligation task using the hinotori surgical robot system on a suture simulator. Median scores and task completion times were compared. RESULTS: Pegboard task scores were 95.0%, 92.0%, and 91.5% for the RS, LS, and N groups, respectively, with differences between the RS group and LS and N groups. Camera and clutch operation scores were 93.1%, 49.7%, and 89.1%, respectively, showing differences between the RS group and LS and N groups. Energizing operation scores were 90.9%, 85.2%, and 95.0%, respectively, with a significant difference between the LS and N groups. Suture sponge task scores were 90.6%, 43.1%, and 46.2%, respectively, with differences between the RS group and LS and N groups. For the suture ligation task, completion times were 368 s, 666 s, and 1095 s, respectively, indicating differences among groups. Suture scores were 12, 10, and 7 points, respectively, with differences between the RS and N groups. CONCLUSION: First-touch simulator-based robotic skills were partially influenced by prior robotic surgical experience, while suturing skills were affected by overall surgical experience. Thus, robotic training programs should be tailored to individual adaptability.2024年11月, Langenbeck's archives of surgery, 409(1) (1), 332 - 332, 英語, 国際誌[査読有り]研究論文(学術雑誌)
- 2024年11月, システム制御情報学会論文誌, 37(11) (11), 275 - 282, 日本語[査読有り]研究論文(学術雑誌)
- 2024年07月, Proc. of 2024 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), 1 - 8, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2024年, Proceedings - 2024 IEEE Cyber Science and Technology Congress, CyberSciTech 2024, 115 - 124, 英語[査読有り]研究論文(国際会議プロシーディングス)
- Institute of Electrical and Electronics Engineers (IEEE), 2024年, IEEE Access, 12, 142101 - 142126, 英語[査読有り]研究論文(学術雑誌)
- 2024年01月, IEICE Trans. Inf. Syst., 107(1) (1), 2 - 12, 日本語[査読有り][招待有り]研究論文(学術雑誌)
- 2023年07月, Journal of Advanced Computational Intelligence and Intelligent Informatics, 27(4) (4), 603 - 608[査読有り][招待有り]研究論文(学術雑誌)
- 2023年01月, Artificial Intelligence in the Age of Neural Networks and Brain Computing, Second Edition, 251 - 267, 英語[査読有り][招待有り]論文集(書籍)内論文
- 2023年, IEEE Access, 11, 102727 - 102745, 英語[査読有り]研究論文(学術雑誌)
- 2022年12月, Applied Sciences, 英語[査読有り]研究論文(学術雑誌)
- 2022年12月, ICONIP (3), 683 - 692, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2022年04月, IEEE Access, 10, 43954 - 43963, 英語[査読有り]研究論文(学術雑誌)
- Information Processing Society of Japan, 2022年, Journal of Information Processing, 30, 789 - 795, 英語[査読有り][招待有り]研究論文(学術雑誌)
- 2022年, IEEE Access, 10, 57383 - 57397, 英語[査読有り]研究論文(学術雑誌)
- MDPI, 2021年11月, Engineering Proceedings, 9(1) (1), 1 - 4, 英語[査読有り]研究論文(学術雑誌)
- IEEE, 2021年07月, International Joint Conference on Neural Networks(IJCNN), 1 - 7, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2021年07月, Neural Information Processing. ICONIP 2021. Lecture Notes in Computer Science, 13109, 669 - 680, 英語[査読有り]研究論文(国際会議プロシーディングス)
- Springer International Publishing, 2020年12月, In: Yang H., Pasupa K., Leung A.CS., Kwok J.T., Chan J.H., King I. (eds) Neural Information Processing. ICONIP 2020. Lecture Notes in Computer Science, vol 12533. Springer, Cham., 593 - 603[査読有り]論文集(書籍)内論文
- Springer International Publishing, 2020年12月, In: Yang H., Pasupa K., Leung A.CS., Kwok J.T., Chan J.H., King I. (eds) Neural Information Processing. ICONIP 2020. Lecture Notes in Computer Science, vol 12533. Springer, Cham., 558 - 569, 英語[査読有り]論文集(書籍)内論文
- 2020年11月, APPLIED SCIENCES-BASEL, 10(22) (22), 英語[査読有り]研究論文(学術雑誌)
- 2020年09月, CAAI TRANSACTIONS ON INTELLIGENCE TECHNOLOGY, 5(3) (3), 184 - 192, 英語[査読有り]研究論文(学術雑誌)
- 2020年07月, 2020 International Joint Conference on Neural Networks (IJCNN), 1 - 8, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2020年07月, 2020 International Joint Conference on Neural Networks (IJCNN), 1 - 7, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2020年02月, INTERNATIONAL JOURNAL OF INFORMATION SECURITY, 19(1) (1), 83 - 92, 英語, 国際誌, 国際共著していない[査読有り]研究論文(学術雑誌)
- 2019年12月, Aust. J. Intell. Inf. Process. Syst., 17(1) (1), 78 - 86, 英語t-Distributed Stochastic Neighbor Embedding Spectral Clustering using higher order approximations.[査読有り]研究論文(学術雑誌)
- 2019年12月, In: Gedeon T., Wong K., Lee M. (eds) Neural Information Processing. ICONIP 2019. Lecture Notes in Computer Science, vol 11955. Springer, Cham., 319 - 327, 英語[査読有り]論文集(書籍)内論文
- IEEE, 2019年11月, 2019 International Conference on Data Mining Workshops (ICDMW), 37 - 44, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2019年11月, APPLIED SOFT COMPUTING, 84, 英語, 国際誌, 国際共著していない[査読有り]研究論文(学術雑誌)
- 2019年09月, ICISIP 2019 : The 7th IIAE International Conference on Intelligent Systems and Image Processing 2019, 278 - 285, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2019年06月, 12th European Federation for Information Technology in Agriculture, Food and the Environment (EFITA) International Conference, 英語Feature Selection and Grouping of Cultivation Environment Data to Extract High/Low Yield Inhibition Factor of Soybeans[査読有り]研究論文(国際会議プロシーディングス)
- Recently, smart agriculture, a new approach to farming using ICT, has been received great attention. To control cultivate condition precisely, it is important to capture the growth state of plants as well as environmental factors such as temperature, moisture, solar radiation, etc. In this paper, we propose an image sensing method to detect soy flowers and seedpods as growth faIEEE SMC, 2018年10月, Proceedings of the 2018 IEEE International Conference on Systems, Man, and Cybernetics, 1 - 6, 英語[査読有り]研究論文(国際会議プロシーディングス)
- Detection of Malicious JavaScript Contents Using Doc2vec Feature LearningTo add more functionality and enhance usability of web applications, JavaScript (JS) is frequently used. Even with many advantages and usefulness of JS, an annoying fact is that many recent cyberattacks such as drive-by-download attacks exploit vulnerability of JS codes. In general, malicious JS codes are not easy to detect, because they sneakily exploit vulnerabilities of browIEEE, 2018年07月, Proc. of 2018 International Joint Conference on Neural Networks, 1 - 7, 英語[査読有り]研究論文(国際会議プロシーディングス)
- Optimal pattern Discovery to Reveal the High Yield Inhibition Factor of SoybeansOur research group is working on soybeans which the quantity of yielding is difficult to predict. We focus on the common characteristics observed at multiple cultivation points, in order to examine methods to acquire new knowledge in deciding the work based on the amount of yields. Our previous study has examined a method to discover optimal patterns using qualitative value of2018年04月, Journal of the Institute of Industrial Applications Engineers (Web), 6(2) (2), 66‐72 (WEB ONLY), 英語[査読有り][招待有り]研究論文(学術雑誌)
- Elsevier, 2018年01月, Artificial Intelligence in the Age of Neural Networks and Brain Computing, 245 - 263, 英語論文集(書籍)内論文
- 2018年, 2018 INTERNATIONAL JOINT CONFERENCE ON NEURAL NETWORKS (IJCNN), 2018-July, 1 - 8, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2018年01月, APPLIED SOFT COMPUTING, 62, 592 - 601, 英語[査読有り]研究論文(学術雑誌)
- 2018年, 2018 IEEE INTERNATIONAL CONFERENCE ON SYSTEMS, MAN, AND CYBERNETICS (SMC), 1693 - 1698, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2018年, INNS CONFERENCE ON BIG DATA AND DEEP LEARNING, 144(144) (144), 118 - 123, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2018年, NEURAL INFORMATION PROCESSING (ICONIP 2018), PT IV, 11304, 349 - 358, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2017年09月, Proceedings of IIAE International Conference on Intelligent Systems and Image Processing (Web), 5th, 209‐216 (WEB ONLY), 英語Optimal Pattern Discovery based on Cultivation Data for Elucidation of High Yield Inhibition Factor of Soybean[査読有り]研究論文(国際会議プロシーディングス)
- There is a high demand to promote efficiency in agriculture, as the number of workers engaging in agriculture has been decreasing and aging in recent years. Our research group is working on soybeans which the quantity of yielding is difficult to predict. We focus on the common characteristics observed at multiple cultivation points, in order to examine methods to acquire new kn産業応用工学会, 2017年07月, The 5th IIAE International Conference on Intelligent Systems and Image Processing 2017 (ICISIP2017), 209 - 216, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2017年, 2017 INTERNATIONAL JOINT CONFERENCE ON NEURAL NETWORKS (IJCNN), 2017-May, 1628 - 1632, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2017年, 2017 INTERNATIONAL JOINT CONFERENCE ON NEURAL NETWORKS (IJCNN), 1787 - 1793, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2017年, NEURAL INFORMATION PROCESSING, ICONIP 2017, PT V, 10638(5) (5), 888 - 896, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2017年, 2017 IEEE SYMPOSIUM SERIES ON COMPUTATIONAL INTELLIGENCE (SSCI), 2017(2) (2), 1350 - 1357, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2017年, 2017 IEEE SYMPOSIUM SERIES ON COMPUTATIONAL INTELLIGENCE (SSCI), 2018-January, 1 - 7, 英語[査読有り]研究論文(国際会議プロシーディングス)
- Association for Computing Machinery, 2016年12月, ACM International Conference Proceeding Series, 19 - 24, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2016年09月, EVOLVING SYSTEMS, 7(3) (3), 173 - 186, 英語[査読有り]研究論文(学術雑誌)
- Springer Verlag, 2016年09月, Evolving Systems, 7(3) (3), 173 - 186, 英語[査読有り]研究論文(学術雑誌)
- 2016年07月, 2016 INTERNATIONAL JOINT CONFERENCE ON NEURAL NETWORKS (IJCNN), 60th, 3364 - 3370, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2016年03月, EVOLVING SYSTEMS, 7(1) (1), 15 - 27, 英語[査読有り]研究論文(学術雑誌)
- In recent years, along with the popularization of SNS, the incidents, which are called flaming, that the number of negative comments surges are on the increase. This becomes a problem for companies because flamings hurt companies' reputation. In order to minimalize the damage of reputation, we propose the method that detects flamings by estimating the sentiment polarities of SNS comments. Because of the unique SNS characteristics such as repetition of same comments, the polarities of words are sometimes wrongly estimated. To alleviate this problem, transfer learning is introduced. In this research, the sentiment polarities of words are trained in every domain. This will enable to extract the words that are domain-specific and dictate the polarity of comments. These words are occurred in retweets. Transfer learning is implemented to non-extracted words by averaging the occurrence probabilities in other domains. These processes keep the polarities of important words that dictate the polarity of comments and modify the wrongly estimated polarities of words. The experimental results show that the proposed method improves the performance of estimating the sentiment polarity of comments. Moreover, flamings can be detected without missing by monitoring time course of the number of negative comments.一般社団法人 電気学会, 2016年03月, 電気学会論文誌 C, 136(3) (3), 340 - 347, 日本語[査読有り]研究論文(学術雑誌)
- 2016年, 2016 INTERNATIONAL JOINT CONFERENCE ON NEURAL NETWORKS (IJCNN), 2016-, 2979 - 2985, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2016年, NEURAL INFORMATION PROCESSING, ICONIP 2016, PT III, 9949, 119 - 128, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2016年, PROCEEDINGS OF THE WORKSHOP ON TIME SERIES ANALYTICS AND APPLICATIONS (TSAA'16), 19 - 24, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2016年, PROCEEDINGS OF 2016 IEEE SYMPOSIUM SERIES ON COMPUTATIONAL INTELLIGENCE (SSCI), 1 - 7, 英語[査読有り]研究論文(国際会議プロシーディングス)
- Multi-dimensional Unfolding (MU) is a method to visualize relevance data between two sets (e.g., preference data) as a single scatter plot. Usually, in the analysis of relevance data, users are interested in which elements are strongly related to each other (e.g., how much an individual likes an item), and not in which elements are irrelevant to each other. However, the conventシステム制御情報学会, 2016年, システム制御情報学会研究発表講演会講演論文集(CD-ROM), 60th, 4p - 252, 日本語
- Institute of Electrical and Electronics Engineers Inc., 2015年09月, Proceedings of the International Joint Conference on Neural Networks, 2015-, 1 - 7, 英語[査読有り]研究論文(国際会議プロシーディングス)
- A Non-Destructive Measurement Method for Agricultural Plants Using Image SensingThis paper presents a non-destructive image sensing method to estimate the height of agricultural plants. In this method, several images are taken by moving a digital camera attached to a single-axis robot, and the two consecutive images with a plant tip are automatically matched using SIFT keypoints. Then, the plant height is estimated from the two images based on the triangul2015年09月, Proc. of Int. Symposium on Applied Electromagnetics and Mechanics, 1 - 2, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 神戸大学大学院工学研究科, 2015年, Memoirs of the Graduate Schools of Engineering and System Informatics Kobe University, 7, 8 - 13, 英語
- 2015年, 2015 INTERNATIONAL JOINT CONFERENCE ON NEURAL NETWORKS (IJCNN), 英語An Autonomous Online Malicious Spam Email Detection System Using Extended RBF Network[査読有り]研究論文(国際会議プロシーディングス)
- In this paper, we propose a new online system that can quickly detect malicious spam emails and adapt to the changes in the email contents and the Uniform Resource Locator (URL) links leading to malicious websites by updating the system daily. We introduce an autonomous function for a server to generate training examples, in which double-bounce emails are automatically collecteScientific Research Publishing, 2015年, Journal of Intelligent Learning Systems and Applications,, 7, 42 - 57, 英語[査読有り]研究論文(学術雑誌)
- 2015年, INNS CONFERENCE ON BIG DATA 2015 PROGRAM, 53, 175 - 182, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2015年, NEURAL INFORMATION PROCESSING, ICONIP 2015, PT IV, 9492, 376 - 383, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2014年06月, NEUROCOMPUTING, 134, 280 - 288, 英語[査読有り]研究論文(学術雑誌)
- In real life, data are not always generated under stationary environments. However, traditional learning systems have normally assumed that the property of data streams is stationary over time, and this sometimes leads to the degradation in the system performance when there are some hidden contexts changes (e.g. changes in class boundaries and temporal trends in time series). SInstitute of Systems, Control and Information Engineers, 2014年04月, Trans. of Institute of Systems, Control and Information Engineers, 27(4) (4), 133 - 140, 英語[査読有り][招待有り]研究論文(学術雑誌)
- 神戸大学大学院工学研究科, 2014年, Memoirs of the Graduate Schools of Engineering and System Informatics Kobe University, 6, 13 - 17, 英語
- 2014年, SMART DIGITAL FUTURES 2014, 262, 402 - 411, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2014年, PROCEEDINGS OF THE 2014 INTERNATIONAL JOINT CONFERENCE ON NEURAL NETWORKS (IJCNN), 3135 - 3142, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2014年, 2014 NINTH ASIA JOINT CONFERENCE ON INFORMATION SECURITY (ASIA JCIS), 39 - 43, 英語[査読有り]研究論文(国際会議プロシーディングス)
- ダークネットトラフィック観測によるDDoSバックスキャッタ判定DDoS攻撃は企業や団体に深刻な経済損害を与える脅威であり,早急にDDoS攻撃を検知することが重要である.本研究では,ダークネットセンサで観測されたパケットトラフィック情報からDDoS攻撃によるバックスキャッタであるか否かを高速に判定する手法を提案する.短時間のパケットデータから送信元/送信先ポートや送信元/送信先IPなどに関連した12の特徴を抽出し,サポートベクターマシーン(SVM)を用いた分類を試みる.評価実験では,バックスキャッタか否かのラベル情報を与えることのできる80番ポートからのTCPパケットと53番ポートからのUDPパケットを用いて,これらの特徴ベクトルからDDoS攻撃によるバックスキャッタか否かの判定を行う.評価実験により,提案手法によって高い精度でバックスキャッタを判別できることを示す.一般社団法人電子情報通信学会, 2014年, 電子情報通信学会技術研究報告, 114(340(ICSS2014 51-62)) (340(ICSS2014 51-62)), 49 - 53, 日本語
- 2014年, 2014 IEEE SYMPOSIUM ON COMPUTATIONAL INTELLIGENCE IN BIG DATA (CIBD), 20 - 25, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2014年, NEURAL INFORMATION PROCESSING, ICONIP 2014, PT III, 8836, 365 - 372, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2013年04月, ELECTRONICS AND COMMUNICATIONS IN JAPAN, 96(4) (4), 29 - 40, 英語[査読有り]研究論文(学術雑誌)
- 2013年, 2013 INTERNATIONAL JOINT CONFERENCE ON NEURAL NETWORKS (IJCNN), 1 - 8, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2013年, 2013 INTERNATIONAL JOINT CONFERENCE ON NEURAL NETWORKS (IJCNN), 1 - 8, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2013年, ARTIFICIAL NEURAL NETWORKS AND MACHINE LEARNING - ICANN 2013, 8131, 162 - 169, 英語[査読有り]研究論文(国際会議プロシーディングス)
- Springer, 2013年, Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), 8226(1) (1), 369 - 376, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 追加学習型主成分分析の高速化と顔画像認識への応用従来の追加学習型主成分分析(IPCA) では, 訓練データが一つまたは少数ずつ与えられるたびに固有値問題を解く必要がある. 一般に固有値計算は計算量が多いため, 繰り返し固有値問題を解くことは, 特に顔画像などの高次元データから特徴を抽出する際, 学習のリアルタイム性を損なうことにつながる. そこで, 本研究では, できるだけ認識性能を保ったまま, 固有値問題を解く回数を減らし, IPCA のリアルタイム実行性を高めた改良手法を提案する.逐次的に入力される顔画像データに対して, 提案した改良型CIPCA アルゴリズムがリアルタイムで主成分特徴を学習できることを示す.社団法人電子情報通信学会, 2012年06月, 信学技報, 112(108) (108), 1 - 6, 日本語研究論文(研究会,シンポジウム資料等)
- Along with the development of the network technology and high-performance small devices such as surveillance cameras and smart phones, various kinds of multimodal information (texts, images, sound, etc.) are captured real-time and shared among systems through networks. Such information is given to a system as a stream of data. In a person identification system based on face recognition, for example, image frames of a face are captured by a video camera and given to the system for an identification purpose. Those face images are considered as a stream of data. Therefore, in order to identify a person more accurately under realistic environments, a high-performance feature extraction method for streaming data, which can be autonomously adapted to the change of data distributions, is solicited. In this review paper, we discuss a recent trend on online feature extraction for streaming data. There have been proposed a variety of feature extraction methods for streaming data recently. Due to the space limitation, we here focus on the incremental principal component analysis.一般社団法人 電気学会, 2012年, 電気学会論文誌 C, 132(1) (1), 6 - 13, 日本語
- IEEE, 2012年, 2012 IEEE Conference on Evolving and Adaptive Intelligent Systems, EAIS 2012 - Proceedings, 7 - 10, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2012年, NEURAL INFORMATION PROCESSING, ICONIP 2012, PT II, 7664, 640 - 647, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2012年, 2012 IEEE INTERNATIONAL CONFERENCE ON DEVELOPMENT AND LEARNING AND EPIGENETIC ROBOTICS (ICDL), 1 - 2, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2012年, 2012 11TH INTERNATIONAL CONFERENCE ON MACHINE LEARNING AND APPLICATIONS (ICMLA 2012), VOL 1, 671 - 674, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2011年12月, Evolving Systems, 2(4) (4), 215 - 217, 英語[査読有り]研究論文(学術雑誌)
- 2011年12月, Evolving Systems, 2(4) (4), 261 - 272, 英語[査読有り]研究論文(学術雑誌)
- 2011年06月, NEURAL PROCESSING LETTERS, 33(3) (3), 283 - 299, 英語[査読有り]研究論文(学術雑誌)
- 2011年, IEEE SSCI 2011: Symposium Series on Computational Intelligence - EAIS 2011: 2011 IEEE Workshop on Evolving and Adaptive Intelligent Systems, 70 - 76, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2011年, 2011 IEEE INTERNATIONAL CONFERENCE ON ACOUSTICS, SPEECH, AND SIGNAL PROCESSING, pp. 1493 - 1496, 1493 - 1496, 英語[査読有り]研究論文(国際会議プロシーディングス)
- This paper proposes a new online feature extraction method called Incremental Recursive Fisher Linear Discriminant (IRFLD) whose batch learning algorithm called RFLD has been proposed by Xiang et al. In the conventional Linear Discriminant Analysis (LDA), the number of discriminant vectors is limited to the number of classes minus one due to the rank of the between-class covariance matrix. However, RFLD and the proposed IRFLD can break this limit; that is, an arbitrary number of discriminant vectors can be obtained. In the proposed IRFLD, the Pang et al.'s Incremental Linear Discriminant Analysis (ILDA) is extended such that effective discriminant vectors are recursively searched for the complementary space of a conventional discriminant subspace. In addition, to estimate a suitable number of effective discriminant vectors, the classification accuracy is evaluated with a cross-validation method in an online manner. For this purpose, validation data are obtained by performing the k-means clustering against incoming training data and previous validation data. The performance of IRFLD is evaluated for 16 benchmark data sets. The experimental results show that the final classification accuracies of IRFLD are always better than those of ILDA. We also reveal that this performance improvement is attained by adding discriminant vectors in a complementary LDA subspace.一般社団法人 電気学会, 2011年, 電気学会論文誌 C, 131(7) (7), 1368 - 1376, 日本語
- 2011年, 2011 INTERNATIONAL JOINT CONFERENCE ON NEURAL NETWORKS (IJCNN), pp. 2911-2916, 2911 - 2916, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2011年, 2011 INTERNATIONAL JOINT CONFERENCE ON NEURAL NETWORKS (IJCNN), pp. 2881-2888, 2881 - 2888, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2011年, Proceedings - 10th International Conference on Machine Learning and Applications, ICMLA 2011, 2, 35 - 40, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2010年12月, Journal of Intelligent Learning Systems and Applications, Vol. 2, No. 4, pp. 200-211, 英語Fast Variable Selection by Block Addition and Block Deletion[査読有り]研究論文(学術雑誌)
- 2010年12月, Journal of Intelligent Learning Systems and Applications, Vol. 2, No. 4, pp. 179-189, 英語An Autonomous Incremental Learning Algorithm for Radial Basis Function Networks[査読有り]研究論文(学術雑誌)
- 2010年08月, Evolving Systems, 1(1) (1), 17 - 27, 英語[査読有り]研究論文(学術雑誌)
- 2010年02月, INTERNATIONAL JOURNAL OF INNOVATIVE COMPUTING INFORMATION AND CONTROL, 6(2) (2), 577 - 590, 英語A REINFORCEMENT LEARNING MODEL USING DETERMINISTIC STATE-ACTION SEQUENCES[査読有り]研究論文(学術雑誌)
- 追加学習型カーネル主成分分析によるオンライン特徴抽出本論文では,初期データにのみ教師情報が与えられる「準教師付き学習タスク」において,ストリーミングデータからオンラインで非線形な特徴を抽出できる追加学習型カーネル主成分分析(IKPCA)を提案する.提案するIKPCAでは,学習データが入力されるたびにカーネル主成分分析の固有値問題を更新し,それを解くことで固有ベクトルの更新を行う.特徴固有空間で一次独立なデータを選択して固有ベクトルを表現するため,データの一次独立性を判定する必要がなく,追加学習時に保持するデータ数が少なくなって学習が高速化される.ベンチマークデータを用いた評価実験において,主成分分析(PCA)と追加学習型主成分分析(IPCA),更にカーネル主成分分析(KPCA)と比較し,IKPCAで得られる特徴量の評価を行った.その結果,IKPCAによってバッチ学習のKPCAと同等の認識性能が得られ,安定した追加学習が行われることを示した.このことは,IKPCAとKPCAにおいて,固有ベクトルや固有値の一致度を調べた実験からも確認された.また,多くの評価データでPCAやIPCAよりも,認識性能の優れた特徴が得られることを示した.一般社団法人電子情報通信学会, 2010年, 電子情報通信学会論文誌 D, J93-D(6) (6), 826 - 836, 日本語
- 2010年, 2010 INTERNATIONAL JOINT CONFERENCE ON NEURAL NETWORKS IJCNN 2010, pp. 706-71, 英語An Autonomous Incremental Learning Algorithm of Resource Allocating Network for Online Pattern Recognition[査読有り]研究論文(国際会議プロシーディングス)
- To avoid the catastrophic interference in incremental learning, we have proposed Resource Allocating Network with Long Term Memory (RAN-LTM). In RAN-LTM, not only new training data but also some memory items stored in long-term memory are trained either by a gradient descent algorithm or by solving a linear regression problem. In the latter approach, radial basis function (RBF) centers are not trained but selected based on output errors when connection weights are updated. The proposed incremental learning algorithm belongs to the latter approach where the errors not only for a training data but also for several retrieved memory items and pseudo training data are minimized to suppress the catastrophic interference. The novelty of the proposed algorithm is that connection weights to be learned are restricted based on RBF activation in order to improve the efficiency in learning time and memory size. We evaluate the performance of the proposed algorithm in one-dimensional and multi-dimensional function approximation problems in terms of approximation accuracy, learning time, and average memory size. The experimental results demonstrate that the proposed algorithm can learn fast and have good performance with less memory size compared to memory-based learning methods.一般社団法人 電気学会, 2010年, 電気学会論文誌 C, 130(9) (9), 1667 - 1673, 日本語
- 2010年, PRICAI 2010: TRENDS IN ARTIFICIAL INTELLIGENCE, 6230, 445 - +, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2010年, PRICAI 2010: TRENDS IN ARTIFICIAL INTELLIGENCE, 6230, 487 - 497, 英語[査読有り]研究論文(国際会議プロシーディングス)
- When environments are dynamically changed for agents, the knowledge acquired in an environment might be useless in future. In such dynamic environments, agents should be able to not only acquire new knowledge but also modify old knowledge in learning. However, modifying all knowledge acquired before is not efficient because the knowledge once acquired may be useful again when similar environment reappears and some knowledge can be shared among different environments. To learn efficiently in such environments, we propose a neural network model that consists of the following modules: resource allocating network, long-term & short-term memory, and environment change detector. We evaluate the model under a class of dynamic environments where multiple function approximation tasks are sequentially given. The experimental results demonstrate that the proposed model possesses stable incremental learning, accurate environmental change detection, proper association and recall of old knowledge, and efficient knowledge transfer.一般社団法人 電気学会, 2010年, 電気学会論文誌 C, 130(1) (1), 21 - 28, 日本語
- 2009年03月, IEEE TRANSACTIONS ON NEURAL NETWORKS, 20(3) (3), 430 - 445, 英語[査読有り]研究論文(学術雑誌)
- Institute of Electrical Engineers of Japan, 2009年, 電気学会論文誌C, 129(4) (4), 21 - 743, 英語[査読有り]研究論文(学術雑誌)
- 2009年, IJCNN: 2009 INTERNATIONAL JOINT CONFERENCE ON NEURAL NETWORKS, VOLS 1- 6, pp. 2401-2408, 1616 - +, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2009年, IJCNN: 2009 INTERNATIONAL JOINT CONFERENCE ON NEURAL NETWORKS, VOLS 1- 6, pp. 2310-2315, 2671 - 2676, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2009年, IJCNN: 2009 INTERNATIONAL JOINT CONFERENCE ON NEURAL NETWORKS, VOLS 1- 6, pp. 2394-2400, 2889 - +, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2009年, ADVANCES IN NEURO-INFORMATION PROCESSING, PT I, 5506, 1196 - +, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2009年, ADVANCES IN NEURO-INFORMATION PROCESSING, PT I, 5506, 1163 - +, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2009年, ADVANCES IN NEURO-INFORMATION PROCESSING, PT I, 5506, 821 - +, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2009年, Memetic Computing, 1(3) (3), 221 - 228, 英語[査読有り]研究論文(学術雑誌)
- 2009年, 2009 IEEE INTERNATIONAL CONFERENCE ON SYSTEMS, MAN AND CYBERNETICS (SMC 2009), VOLS 1-9, 6 pages, 3088 - 3093, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2009年, INTELLIGENT DATA ENGINEERING AND AUTOMATED LEARNING, PROCEEDINGS, 5788, 134 - +, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2009年, NEURAL INFORMATION PROCESSING, PT 1, PROCEEDINGS, 5863, 562 - 569, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2008年06月, IEEE TRANSACTIONS ON NEURAL NETWORKS, 19(6) (6), 1061 - 1074, 英語[査読有り]研究論文(学術雑誌)
- 2008年, 2008 PROCEEDINGS OF SICE ANNUAL CONFERENCE, VOLS 1-7, 2370 - +, 英語An Incremental Principal Component Analysis Based on Dynamic Accumulation Ratio[査読有り]研究論文(国際会議プロシーディングス)
- 2008年, NEURAL INFORMATION PROCESSING, PART II, 4985, 396 - +, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2008年, SEVENTH INTERNATIONAL CONFERENCE ON MACHINE LEARNING AND APPLICATIONS, PROCEEDINGS, pp. 747- 751, 747 - +, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2007年11月, IEICE TRANSACTIONS ON INFORMATION AND SYSTEMS, E90D(11) (11), 1853 - 1863, 英語[査読有り]研究論文(学術雑誌)
- 2007年, IEEE International Conference on Neural Networks - Conference Proceedings, 2346 - 2351, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2007年, PROCEEDINGS OF SICE ANNUAL CONFERENCE, VOLS 1-8, 1963 - 1966, 英語An online face recognition system with incremental learning ability[査読有り]研究論文(国際会議プロシーディングス)
- 2007年, 2007 IEEE INTERNATIONAL JOINT CONFERENCE ON NEURAL NETWORKS, VOLS 1-6, CD-ROM (6 pages), 2346 - 2351, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2007年, 2007 INTERNATIONAL SYMPOSIUM ON INTELLIGENT SIGNAL PROCESSING AND COMMUNICATION SYSTEMS, VOLS 1 AND 2, CD-ROM (4 pages), 674 - +, 英語Boosting Kernel Discriminant Analysis for pattern classification[査読有り]研究論文(国際会議プロシーディングス)
- Independent component analysis (ICA) is a technique of transforming observation signals into their unknown independent components; hence ICA has been often applied to blind signal separation problems. In this application, it is expected that the obtained independent components extract essential information of independent signal sources from input data in an unsupervised fashion. Based on such characteristics, ICA is recently utilized as a feature extraction method for images and sounds for recognition purposes. However, since ICA is an unsupervised learning, the obtained independent components are not always useful in recognition. To overcome this problem, we propose a supervised approach to ICA using category information. The proposed method is implemented in a conventional three-layered neural network, but its objective function to be minimized is defined for not only the output layer but also the hidden layer. The objective function consists of the following two terms: one evaluates the kurtosis of hidden unit outputs and the other evaluates the error between output signals and their teacher signals. The experiments are performed for some standard datasets to evaluate the proposed algorithm. It is verified that higher recognition accuracy is attained by the proposed method as compared with a conventional ICA algorithm.一般社団法人 電気学会, 2006年04月, 電気学会論文誌. C, 電子・情報・システム部門誌 = The transactions of the Institute of Electrical Engineers of Japan. C, A publication of Electronics, Information and System Society, 126(4) (4), 542 - 547, 日本語
- 2006年02月, Proc. Int. Workshop on Fuzzy Systems & Innovational Computing (FIC2004) 1 (CD-ROM), 2(1) (1), 181 - 192, 英語On-line Feature Selection for Adaptive Evolving Connectionist[査読有り]研究論文(学術雑誌)
- Institute of Electrical and Electronics Engineers Inc., 2006年, IEEE International Conference on Neural Networks - Conference Proceedings, 3421 - 3427, 英語研究論文(国際会議プロシーディングス)
- 2006年, INTERNATIONAL CONFERENCE ON COMPUTATIONAL INTELLIGENCE FOR MODELLING, CONTROL & AUTOMATION JOINTLY WITH INTERNATIONAL CONFERENCE ON INTELLIGENT AGENTS, WEB TECHNOLOGIES & INTERNET COMMERCE, VOL 1, PROCEEDINGS, Vol. 1, pp. 595-600, 595 - +, 英語Incremental kernel PCA for online learning of feature space[査読有り]研究論文(国際会議プロシーディングス)
- 2006年01月, International Journal of Knowledge-Based & Intelligent Engineering Systems, Vol. 10, No. 1, pp. 57-65, 英語Incremental Learning of Feature Space and Classifier for On-Line Pattern Recognition[査読有り]研究論文(学術雑誌)
- 2006年, 2006 IEEE INTERNATIONAL CONFERENCE ON FUZZY SYSTEMS, VOLS 1-5, pp. 10493-10500, 2278 - +, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2006年, 2006 IEEE INTERNATIONAL JOINT CONFERENCE ON NEURAL NETWORK PROCEEDINGS, VOLS 1-10, pp. 6453-6459, 3421 - +, 英語An incremental learning algorithm of ensemble classifier systems[査読有り]研究論文(国際会議プロシーディングス)
- 2005年10月, IEEE TRANSACTIONS ON SYSTEMS MAN AND CYBERNETICS PART B-CYBERNETICS, 35(5) (5), 905 - 914, 英語[査読有り]研究論文(学術雑誌)
- 2005年10月, NEURAL PROCESSING LETTERS, 22(2) (2), 113 - 124, 英語[査読有り]研究論文(学術雑誌)
- 2005年06月, NEURAL NETWORKS, 18(5-6) (5-6), 575 - 584, 英語[査読有り]研究論文(学術雑誌)
- Applications of independent component analysis (ICA) to feature extraction have been a topic of research interest. However, the effectiveness of pattern features extracted by conventional ICA algorithms greatly depends on datasets in general. As one of the reasons, we have pointed out that conventional ICA features are obtained by increasing only their independence even if class information is available. In this paper, we propose a supervised learning approach to ICA to extract useful and robust features. The proposed method consists of several modules, each of which is responsible for extracting features for each class and identifying the class labels using the k nearest neighbor classifier. All the module outputs are combined to identify final results based on a majority rule. We evaluate the performance of the proposed method in several recognition tasks. From these results, we confirm the effectiveness of the recognition method using independent components for each class.一般社団法人 電気学会, 2005年05月, 電気学会論文誌. C, 電子・情報・システム部門誌 = The transactions of the Institute of Electrical Engineers of Japan. C, A publication of Electronics, Information and System Society, 125(5) (5), 807 - 812, 日本語
- 2005年, Adaptive and Natural Computing Algorithms, 429 - 432, 英語Boosting Kernel discriminant analysis with adaptive Kernel selection[査読有り]研究論文(国際会議プロシーディングス)
- 2005年, ADVANCES IN NEURAL NETWORKS - ISNN 2005, PT 2, PROCEEDINGS, 3497, 51 - 56, 英語Chunk incremental LDA computing on data streams[査読有り]研究論文(学術雑誌)
- 2005年, Proceedings of the International Joint Conference on Neural Networks (IJCNN), 5, 3174 - 3179, 英語[査読有り]研究論文(国際会議プロシーディングス)
- 2004年12月, NEUROCOMPUTING, 62, 427 - 440, 英語[査読有り]研究論文(学術雑誌)
- When training samples are given incrementally, neural networks often suffer from the catastrophic interference, which results in forgetting input-output relationships acquired in the past. To avoid the catastrophic interference, we have proposed Resource Allocating Network with Long-Term Memory (RAN-LTM). In RAN-LTM, not only a new training sample but also some memory items stored in long-term memory are used for training based on a gradient descent algorithm. In general, the gradient descent algorithm is usually slow and can be easily fallen into local minima. In this paper, to alleviate these problems, we introduce a linear regression approach into the learning of RAN-LTM, in which its centers are not trained but selected based on output errors in an incremental fashion. In this approach, the regression is carried out for not only a training sample and memory items but also pseudodata that are selected around the centers of hidden units based on the complexity of an approximated function. This selection reduces the total number of pseudodata at each learning step; as a result, fast incremental learning is realized in RAN-LTM. Since only memory items are stored in memory, the proposed RAN-LTM does not need so much memory capacity when the incremental learning is carried out. This property is useful especially for small-scale systems. To verify these characteristics of RAN-LTM, we apply it to several function approximation problems, in which the performance in approximation accuracy, learning time, and needed memory capacity are investigated by comparison with some conventional models. Moreover, when extending the learning domain with time, the increase trends in learning time and needed memory capacity are investigated. From the experimental results, it is verified that the proposed model can learn fast and accurately, and that it needs rather small memory capacity so far as the learning domain is not too large.公益社団法人 計測自動制御学会, 2004年, 計測自動制御学会論文集, 40(12) (12), 1227 - 1235, 日本語
- Recently, Independent Component Analysis (ICA) has been applied to not only problems of blind signal separation, but also feature extraction of patterns. However, the effectiveness of pattern features extracted by conventional ICA algorithms depends on pattern sets; that is, how patterns are distributed in the feature space. As one of the reasons, we have pointed out that ICA features are obtained by increasing only their independence even if the class information is available. In this context, we can expect that more high-performance features can be obtained by introducing the class information into conventional ICA algorithms.一般社団法人 電気学会, 2004年01月, 電気学会論文誌. C, 電子・情報・システム部門誌 = The transactions of the Institute of Electrical Engineers of Japan. C, A publication of Electronics, Information and System Society, 124(1) (1), 157 - 163, 日本語
In this paper, we propose a supervised ICA (SICA) that maximizes Mahalanobis distance between features of different classes as well as maximize their independence. In the first experiment, two-dimensional artificial data are applied to the proposed SICA algorithm to see how maximizing Mahalanobis distance works well in the feature extraction. As a result, we demonstrate that the proposed SICA algorithm gives good features with high separability as compared with principal component analysis and a conventional ICA. In the second experiment, the recognition performance of features extracted by the proposed SICA is evaluated using the three data sets of UCI Machine Learning Repository. From the results, we show that the better recognition accuracy is obtained using our proposed SICA. Furthermore, we show that pattern features extracted by SICA are better than those extracted by only maximizing the Mahalanobis distance. - 2004年, Proc.of 7th International Conference on Adaptive and Natural Computing Algorithm, 英語A Memory-based Reingorcement Learning Model Utilizing Macro-Actions[査読有り]研究論文(国際会議プロシーディングス)
- 2004年, 2004 IEEE INTERNATIONAL CONFERENCE ON FUZZY SYSTEMS, VOLS 1-3, PROCEEDINGS, 437 - 442, 英語A memory-based neural network model for efficient adaptation to dynamic environments[査読有り]研究論文(国際会議プロシーディングス)
- 2004年, NEURAL INFORMATION PROCESSING, 3316, 1052 - 1057, 英語Supervised independent component analysis with class information[査読有り]研究論文(学術雑誌)
- 2004年, BIOMETRIC AUTHENTICATION, PROCEEDINGS, 3072, 155 - 161, 英語One-pass incremental membership authentication by face classification[査読有り]研究論文(学術雑誌)
- 2004年, PRICAI 2004: TRENDS IN ARTIFICIAL INTELLIGENCE, PROCEEDINGS, 3157, 231 - 240, 英語A modified incremental principal component analysis for on-line learning of feature space and classifier[査読有り]研究論文(学術雑誌)
- It is important to detect gas leakage sounds from pipes in petroleum refining plants and chemical plants, as often the gas used in these plants are flammable or poisonous. In order to detect the leakage accurately, we should select a feature extraction method for sounds properly. The purpose of this paper is to examine whether independent component analysis (ICA) is useful as a feature extraction method. Several experiments are performed in a plant using an artificial gas leakage device under various experimental conditions. A separating matrix that separates the independent components from collected leakage sounds and background noises is trained by an ICA algorithm. Through several simulations, we find that most basis functions acquired from this training are localized in frequency. Furthermore, there are remarkable differences in amplitude of some independent components between leakage sounds and background noises. From these results, we confirm that the feature extraction using the ICA algorithm is very useful for detecting gas leakage sounds.システム制御情報学会, 2003年10月, システム制御情報学会論文誌, 16(10) (10), 539 - 547, 日本語
- 2003年09月, Proceedings of the International Joint Conference on Neural Networks, 1, 102 - 107A Fast Incremental Learning Algorithm of RBF Networks with Long-Term Memory
- In reinforcement learning problems, the agent learns what to do so as to maximize numerical rewards. In many cases, the agent learns its proper actions through the estimation of an action-value function. When the agent's states are continuous, the action-value function cannot be represented by a lookup table in general. A solution for this problem is that a neural network is utilized for approximating it. However, when neural networks are trained incrementally, input-output relationships that are trained formerly tend to be collapsed by given new data. This phenomenon is called “interference”. Since the rewards are incrementally given from the environment, the interference could be also serious in reinforcement learning problems. To solve this problem, we propose a memory-based reinforcement learning model that is composed of Resource Allocating Network and memory. The distinctive feature of the proposed model is that it needs quite a small main memory to execute the accurate learning of action-value functions. To examine this feature, the proposed model is applied to the two conventional problems: Random Walk Task and Extended Mountain-Car Task. In these tasks, the learning domains are temporally expanded in order to evaluate the incremental learning ability. In the simulations, we verify that the proposed model can approximate proper action-value functions with quite a small main memory as compared with the conventional approaches.公益社団法人 計測自動制御学会, 2003年, 計測自動制御学会論文集, 39(12) (12), 1129 - 1135, 日本語
- When the environment is dynamically changed for agents, knowledge acquired from an environment might be useless in the future environments. Therefore, agents should not only acquire new knowledge but also modify or delete old knowledge. However, this modification and deletion are not always efficient in learning. Because the knowledge once acquired in the past can be useful again in the future when the same environment reappears. To learn efficiently in this situation, agents should have memory to store old knowledge. In this paper, we propose an agent architecture that consists of four modules: resource allocating network (RAN), long-term memory (LTM), association buffer (A-Buffer), and environmental change detector (ECD). To evaluate the adaptability in a class of dynamic environments, we apply this model to a simple problem that some target functions to be approximated are changed in turn.一般社団法人 システム制御情報学会, 2003年, システム制御情報学会 研究発表講演会講演論文集, 3(0) (0), 5506 - 5506, 英語
- 2003年, Proc. ANZIIS 2003, 155-161, 英語A Face Recognition System Using Neural Networks with Incremental Learning Ability.[査読有り]研究論文(国際会議プロシーディングス)
- Since the training of support vector machines needs to solve the dual problem with the number of variables equal to the number of training data, the training becomes slow when the number of training data is large. To speed up training the Sequential Minimal Optimization (SMO) technique has been proposed, in which two data are optimized simultaneously. In this paper, we propose to extend SMO so that more than two data are optimized simultaneously. Namely, we select a working set including variables, solve the equality constraint for one variable included in the working set, and substitute it into the objective function. Then we solve the subproblem related to the working set by calculating the inverse of the Hessian matrix. We evaluate our method for the five benchmark data sets and show the speed-up of training over SMO.システム制御情報学会, 2002年11月, システム制御情報学会論文誌, 15(11) (11), 607 - 614, 日本語
- 2002年01月, ICONIP 2002 - Proceedings of the 9th International Conference on Neural Information Processing: Computational Intelligence for the E-Age, 5, 2566 - 2570
- In this paper, an approach to feature extraction utilizing independent component analysis (ICA) is pro-posed. In our approach, input patterns are transformed into feature vectors using ICA-bases that are obtained through two-layer neural network learning. A k-NN classifier is applied to these ICA feature vectors when the recognition accuracy is evaluated. Hand-written digits in MNIST database are used as target characters. Fast ICA algorithm is applied to these images in order to learn ICA-bases. In recognition experiments, we demonstrate that the ICA approach realizes a potential feature extraction method for hand-written digits. Furthermore, we show the addition of noise patterns to training data is effective for elimination of redundant basis functions.一般社団法人 電気学会, 2002年, 電気学会論文誌. C, 122(3) (3), 465 - 470, 日本語
- When neural networks are trained incrementally, input-output relations that are trained formerly tend to be collapsed by the learning of new data. This phenomenon is often called interference. To suppress the interference efficiently, we propose an incremental learning model, in which Long-Term Memory (LTM) is introduced into Resource Allocating Network (RAN) proposed by Platt. This type of memory is utilized for storing useful training data (called LTM data) that are generated adaptively in the learning phase. When a new training datum is given, the proposed system searches several LTM data that are useful for suppressing the interference. The retrieved LTM data as well as the new training datum are trained simultaneously in RAN. In the simulations, the proposed model is applied to various incremental learning problems to evaluate the function approximation accuracy and the learning speed. From the simulation results, we certify that the proposed model can attain good approximation accuracy with small computation costs.公益社団法人 計測自動制御学会, 2002年, 計測自動制御学会論文集, 38(9) (9), 792 - 799, 日本語
- 2001年, KNOWLEDGE-BASED INTELLIGENT INFORMATION ENGINEERING SYSTEMS & ALLIED TECHNOLOGIES, PTS 1 AND 2, 69, 22 - 26, 英語Learning action-value functions using neural networks with incremental learning ability[査読有り]研究論文(国際会議プロシーディングス)
- 2001年01月, Proceedings of the International Joint Conference on Neural Networks, 3, 1989 - 1994Reducing computations in incremental learning for feedforward neural network with long-term memory
- A main problem with dynamical associative memories (DAMs) is that when memory patterns are stored, pseudo-memories (false fixed points and limit cycles) are also generated and they hinder proper association of input patterns. To overcome this problem, Hassoun proposed a heuristic method of reducing pseudo-memories. In this method, DAMs are constructed such that a zero vector called “ground state” as well as stored patterns is stabilized and sparsely activated states (sparse patterns) converge to the ground state. Such dynamical properties of neural networks can be described with linear inequalities, and connection weights of networks are obtained by solving these inequalities using the Ho-Kashyap algorithm. In this paper, we propose an extended Hassoun model in which network dynamics are modified such that dense patterns, mix-ture patterns and inhibition patterns are also converged to the ground state. In simulations, we compare association performance of this extended Hassoun model with conventional associative memory models, and demonstrate the usefulness of our proposed model as a dynamical associative memory.一般社団法人 電気学会, 2001年, 電気学会論文誌. C, 121(5) (5), 899 - 905, 日本語
- The detection of gas leakage sound from pipes is important in petroleum refining plants and chemical plants, as often the gas used in these plants are flammable or poisonous. In order to establish the acoustic diagnosis technique for the leakage sound, we examined the application of modular neural networks to the stable detection. The modular neural network has the ability to adapt its structure according to the environment. Experiments were performed for an artificial gas leakage device with various experimental conditions to imitate the change of environment for a long term. The discrimination accuracy with the proposed network was observed to be about 93%. From the results, we confirmed the effectiveness for the application of the modular neural network to the detection of the leakage sound for the practical use.計測自動制御学会, 2000年09月, 計測自動制御学会論文集, 36(9) (9), 797 - 803, 日本語
- In this paper we discuss training of three-layered neural network classifiers by solving inequalities. Namely, first we represent each class by the center of the training data belonging to the class, and determine the set of hyperplanes that separate each class (i.e., each center) into a single region. Then according to whether the center is on the positive or negative side of the hyperplane, we determine the target values of each class for the hidden neurons (i.e., hyperplanes). Since the convergence condition of the neural network classifier is now represented by the two sets of inequalities, we solve the sets successively by the Ho-Kashyap algorithm. We demonstrate the advantage of our method over the backpropagation algorithm using several benchmark data sets.一般社団法人 システム制御情報学会, 2000年06月, システム制御情報学会論文誌, 13(6) (6), 276 - 283, 日本語
- 2000年, IJCNN 2000: PROCEEDINGS OF THE IEEE-INNS-ENNS INTERNATIONAL JOINT CONFERENCE ON NEURAL NETWORKS, VOL III, 3, 555 - 560, 英語Training three-layer neural network classifiers by solving inequalities研究論文(国際会議プロシーディングス)
- In this paper, we propose an evolutionary approach to architecture design of modular dynamical neural networks. As one of modular dynamical neural networks, we adopt Cross-Coupled Hopfield Nets (CCHN) in which plural Hopfield networks are coupled to each other. The architecture of CCHN is represented by some structural-parameters such as the number of modules, the numbers of units per module, the module connectivity, and so forth. In the proposed design method, these structural-parameters are treated as phenotype of an individual, and suitable modular architecture is searched through the evolution of its genetic representation (genotype) by using genetic algorithms. Based on a simple direct coding method, the order of length of genetic representation for the structural-parameters can be estimated to be O(N2) where N is the total number of units. On the other hand, the order of genetic representation proposed here is O(N). To verify the usefulness of proposed method, we apply a CCHN to associative memories. Here, the fitness of an individual is defined so as to be larger when a CCHN has a simpler architecture as well as when the association performance is higher. As the result of simulations, we certify that the proposed design method can find high-performance CCHN with simple modular architectures.公益社団法人 計測自動制御学会, 2000年, 計測自動制御学会論文集, 36(3) (3), 298 - 305, 日本語
- We describe what characteristics an independent component analysis can extract from Japanese continuous speech. Speech data was selected from ATR database uttered by a female speaker. The data was recorded at 20kHz sampling frequency and was pre-processed with a whitening filter. The learning algorithm of a network was an information-maximization approach proposed by Bell and Sejnowski. After the learning, most of the basis functions that are columns of a mixing matrix were localized in both time and frequency. Furthermore, we confirmed that there were some basis functions to extract the acoustic feature such as the pitch and the formant of each vowel.公益社団法人 計測自動制御学会, 2000年, 計測自動制御学会論文集, 36(5) (5), 456 - 458, 日本語
- It was reported that a sparse coding algorithm produced a set of basis functions being spatially localized, oriented, and bandpass for natural images. The application of Independent Component Analysis (ICA) to the natural images has shown to be similar results to the sparse coding's result. However, the ICA can be applied in the case of basis function matrices to be non-singular and invertible. There are not such limitations in the sparse coding algorithm. This property allows that the code is overcomplete, that is, the number of code elements is greater than the effective dimensionality of the input space. The purpose of this paper is to examine what characteristics of speech the sparse coding algorithm extracts from natural sounds. Speech data was Japanese five vowels uttered by a female speaker during about 1sec. Most of the basis functions were localized in frequency after the training. Some basis functions only shifted in time and resembled each other. Each basis function was compared with the speech data and the result was that some basis functions responded selectively to each vowel. The frequency analysis for the basis function showed that some basis functions extracted the pitch frequency and the formant of each vowel.一般社団法人 電気学会, 2000年, 電気学会論文誌. C, 120(12) (12), 1996 - 2002, 日本語
- IEEE, 1999年, International Conference on Knowledge-Based Intelligent Electronic Systems, Proceedings, KES, 145 - 148, 英語Evolution of a dynamical modular neural network and its application to associative memories研究論文(学術雑誌)
- IEEE, 1999年, Proceedings of the International Joint Conference on Neural Networks, 5, 2981 - 2984, 英語Application of independent component analysis to feature extraction of speech研究論文(国際会議プロシーディングス)
- IEEE, 1999年, International Conference on Knowledge-Based Intelligent Electronic Systems, Proceedings, KES, 149 - 152, 英語Emergence of feature extraction function using genetic programming研究論文(学術雑誌)
- IEEE, 1999年, Proceedings of the International Joint Conference on Neural Networks, 4, 2867 - 2871, 英語Application of independent component analysis to hand-written Japanese character recognition研究論文(国際会議プロシーディングス)
- Kluwer Academic Publishers, 1999年, Neural Processing Letters, 10(2) (2), 97 - 109, 英語[査読有り]研究論文(学術雑誌)
- John Wiley and Sons Inc., 1998年, Electrical Engineering in Japan (English translation of Denki Gakkai Ronbunshi), 125(2) (2), 27 - 34, 英語研究論文(学術雑誌)
- Springer Verlag, 1998年, Biological Cybernetics, 78(1) (1), 19 - 36, 英語[査読有り]研究論文(学術雑誌)
- In this paper, we propose a new autoassociative memory model which is derived from Cross-Coupled Hopfield Nets (CCHN). The CCHN is a modular neural network in which plural Hopfield networks are mutually connected via feedforward neural networks. The CCHN's architecture is determined by the following structural parameters : the number of modules, the numbers of units in the modules, the contribution of the module information processings and the interactions to the whole network information processing, and the module connectivity. If these parameters are changed, the network dynamics are also changed; therefore, it may be possible to implement a great number of autoassociative memories with different nature. Through some computer simulations, we will discuss a diversity of association properties in the proposed model.一般社団法人 システム制御情報学会, 1997年12月, システム制御情報学会論文誌, 10(12) (12), 668 - 678, 日本語
- In this paper, the association characteristics of Cross-Coupled Hopfield Nets (CCHN) proposed as a modular neural network model are discussed in an analytical way. In the CCHN, an arbitrary number of modules (Hopfield networks) can be mutually connected via feedforward networks called “internetworks”, whose outputs generate the interactions among module networks. To evaluate the CCHN as a modular neural network, it has been applied to associative memories so far. Although its excellent association performance is supported by many simulation results, it is still difficult to compute the memory capacity exactly and examine the dynamical properties rigorously, because the information processing of the CCHN includes strong nonlinearity. Hence, as the first step to the analytical approach, this paper focuses on a 1-module CCHN whose interaction is realized by a two-layered feedforward internetwork. In this case, the connection matrix of the CCHN degenerates into a single square-matrix like a conventional auto-association type of associative memory. Through the eigenvalue analysis for the connection matrix, we reveal that the essential differences between the association characteristics of the CCHN and a conventional auto-correlation associative memory originate from the dynamics in the noise-space which is the orthogonal complement of the subspace generated from memory patterns.一般社団法人 電気学会, 1997年, 電気学会論文誌. C, 117(9) (9), 1253 - 1258, 日本語
- モジュール化ニューラルネットモデルの提案とその連想記憶能力の評価本論文では,モジュール構造をもつニューラルネット(モジュール化ニューラルネット)のモデル化手法として,情報処理様式をエネルギー関数で記述する方法を採用する.この一モデルとして,モジュールネットの情報処理とモジュールネット間の相互作用に対するエネルギー関数を線形に加算し,更にモジュールネットの状態間に多対多の写像関係がある場合でも適用可能としたCross-Coupled Nets With Many-to-Many Mapping Internetworks(CCHN-MMMI)を提案する.また,CCHN-MMMIのネットワークダイナミックスを導出し,モジュール数が2であるCCHN-MMMIの想起特性とその連想記億能力をシミュレーション実験により調べる.シミューレーション実験では,モジュール構造が明示的に与えられることによる効果を,その想起過程から従来の自己相関型連想記億モデルとの比較により考察する.次に,文字パターン対の連想を例にとり,モジュールネットの状態間に多対多の写像関係がある場合でも正しく動作することを確認する.また,基本記憶をランダムに選んだとき,その数の増加に伴う想起ダイナミックスの劣化を定量的に調べ,連想記憶モデルとしての評価を行う.その結果,さまざまな基本記憶に対し,CCHN-MMMIはモジュールネットの状態間に多対多の写像関係がある場合でも正しく動作し,その相互作用は偽記憶の想起を妨げるよう機能することがわかった.特に,モジュールネット間の写像関係を多層ネットワークで学習するCCHN-MMMIでは,自己相関型連想記憶モデルに比べ大幅に連想能力が改善され,モジュールネット間に非線形な相互作用をもつことの効果が確認された.電子情報通信学会, 1994年06月, 電子情報通信学会論文誌. D-II, 情報・システム, II-情報処理, 77(6) (6), 1135 - 1145, 日本語
- 2025年03月07日, 信学技報, 124(422) (422), 375 - 382, 日本語不正検知回避のための金融取引データ生成モデル機関テクニカルレポート,技術報告書,プレプリント等
- 不確実なデータラベルを前提とした機械学習によるサイバー攻撃検知のための誤ラベル訂正機械学習は,さまざまな課題においてデータに基づいてモデル構築を実現しているが,サイバー攻撃検知において正確なラベルが付与されないため高い精度を実現できない問題がある.本稿では,不確実なデータラベルを前提とした機械学習によるサイバー攻撃検知のための誤ラベル訂正手法を提案する.従来手法であるConfident Learningは,画像分類など汎用的なタスクにおいてクラスの組ごとに独立に誤ラベルが発生する場合に対応できる.しかしながら,サイバー攻撃検知においては,正例と負例の均衡がとれていない場合が多い.また,インシデントに基づいて運用者がラベル付けを行うため,時刻がずれることによって発生する誤ラベルが多い.本稿では,Confident Learningを拡張して,データセットの不均衡性と時刻のずれに対して頑強な誤ラベル訂正手法を提案する.提案手法の有効性を検証するために,公開されているCICIDS2017データセットおよび,企業ネットワークに設置された侵入検知システムのログを用いて評価した.その結果,提案手法は,従来手法に比べて高い精度で誤ラベルを訂正できることが分かった.また,侵入検知システムのログにおいて,ラベル時刻のずれを訂正できることを確認した. Machine learning has enabled model development based on data across various domains. However, in cyber-attack detection, the lack of accurate labels hinders high accuracy. This paper proposes a method for correcting mislabeled data in cyber-attack detection using machine learning, assuming uncertain data labels. Confident Learning, a conventional method, can handle situations where label errors occur independently within each class in general tasks such as image classification. However, in cyber-attack detection, there is often a significant imbalance between positive and negative labels. Additionally, since labels are assigned by operators based on incidents, mislabeling regarding time discrepancies frequently occurs. This paper proposes an extension of Confident Learning that provides a robust method for correcting mislabeled data, addressing both dataset imbalance and time discrepancies. To validate the effectiveness of the proposed method, we evaluated it using the publicly available CICIDS2017 dataset and logs from an IDS(Intrusion Detection System) deployed in an enterprise network. The results demonstrate that the proposed method can correct mislabeled data with higher accuracy compared to conventional methods. Furthermore, we confirmed that the method can correct time discrepancies in the labels within the IDS logs.2024年10月15日, コンピュータセキュリティシンポジウム2024論文集, 76 - 83, 日本語
- 2024年05月01日, オペレーションズ・リサーチ, 69(5) (5), 241 - 246, 日本語組織間水平連合学習による社会実装[査読有り][招待有り]記事・総説・解説・論説等(学術雑誌)
- 2024年03月, 電子情報通信学会技術研究報告(Web), 123(423(IT2023 117-135)) (423(IT2023 117-135)), 日本語継続学習型連合学習モデルにおける効率的なリプレイデータの選択機関テクニカルレポート,技術報告書,プレプリント等
- 大規模言語モデルによるセキュリティ対策の視覚認知メカニズムのモデル化に向けた検討フィッシングのようなサイバー攻撃では,ユーザ自身による対策が求められる.セキュリティ教育において,フィッシングの場合は,攻撃の特徴を記憶し,それらとWebサイトを比較することによって攻撃を判断するように教育される.しかし,日々進化するサイバー攻撃への対策として,新しい攻撃手法を学び直し続けることはユーザの大きな負担となる.本稿では,大規模言語モデル(LLM:Large Largeage Models)によるセキュリティ対策における視覚的認知メカニズムのモデル化に向けた分析方式を提案する.近年,LLMは,人間のフィードバックによるファインチューニングによって因果推論タスクが可能になってきている.しかし,LLMは,言語によって記述されていないタスクの取り扱いが難しい.そこで,提案方式は,視覚的認知の情報を言語化することによって,LLMによる視覚的認知メカニズムのモデル化を目指す.提案方式の有効性を検証するために,フィッシングサイトと正規サイトをそれぞれ110件用いて評価を行った.その結果,大規模言語モデルと視覚情報だけを用いて,適合率98.2\%,再現率83.7\%の精度でフィッシングサイトを検知できた.さらに,フィッシング対策の文書をLLMに与えて判定過程を観察することによって,人間の認知メカニズムとLLMの振る舞いの関連性を調査した.また,フィッシング判定以外の複数のセキュリティ判定タスクに対するLLMの有効性を明らかにした.今後は,ユーザを狙うさまざまなサイバー攻撃に本手法を拡大して,視覚的認知メカニズムをモデル化することによってセキュリティ対策および教育への応用を検討する. Cyber attacks such as phishing require users to take their own countermeasures. In security education, in the case of phishing, users are taught to memorize the characteristics of the attack and to judge the attack by comparing the attack with the website. However, it is a heavy burden for users to keep learning and relearning new attack methods to counter cyber attacks that are evolving day by day. In this paper, we propose an analysis method for modeling visual cognitive mechanisms in security countermeasures using large language model. Recently, large language model have become capable of performing causal inference tasks through fine tuning with human feedback. However, large language model have difficulty in handling tasks that are not described by language. Therefore, the proposed method aims at modeling visual cognition mechanisms using language model by converting visual cognition information into language. To verify the effectiveness of the proposed method, we conducted an evaluation using 110 phishing sites and legitimate sites, respectively. The results showed that the proposed method was able to detect phishing sites with an accuracy of 98.2\% and 83.7\% using only a large language model and visual information.Furthermore, we investigated the relevance to human cognitive mechanisms by qualitatively comparing the phishing decision process with a large language model given an anti-phishing document. We also clarified the effectiveness of the model in phishing attacks other than phishing sites. In the future, we will apply the model to security attacks other than phishing to realize security countermeasures and education based on cognitive mechanisms.2023年10月23日, コンピュータセキュリティシンポジウム2023論文集, 1536 - 1543, 日本語研究発表ペーパー・要旨(全国大会,その他学術会議)
- Springer, 2023年04月, Lecture Notes in Computer Science, 13625, 英語[招待有り]研究発表ペーパー・要旨(国際会議)
- Springer, 2023年04月, Lecture Notes in Computer Science, 13624, 英語[査読有り]
- Springer International Publishing, 2023年04月, Lecture Notes in Computer Science, 13624, 英語[査読有り]
- Springer, 2023年04月, Lecture Notes in Computer Science, 1794, 英語[査読有り]
- Springer, 2023年04月, Lecture Notes in Computer Science, 1792, 英語[査読有り]
- Springer, 2023年04月, Lecture Notes in Computer Science, 1791, 英語[査読有り]
- 2023年, 人工知能学会第二種研究会資料(Web), 2023(FIN-031) (FIN-031)ChatGPTを用いたニュース記事のESGトピック分析
- 2023年, 日本コンピュータ外科学会誌(Web), 25(3) (3)YOLOv8ファインチューニングによる手術ロボットhinotoriに対する縫合タスクにおける器具検出・セグメンテーション
- 2023年, 日本コンピュータ外科学会誌(Web), 25(3) (3)医療ロボットhinotoriのログ活用によるスキル評価
- 2023年, 日本コンピュータ外科学会誌(Web), 25(3) (3)ロボット支援手術における手技映像と操作ログの時間同期
- 2023年, 人工知能学会全国大会論文集(Web), 37th対照学習済みBERTによる不祥事記事分類と文章埋め込み表現の考察
- Springer, 2023年, Lecture Notes in Computer Science, 1793, 英語[査読有り]
- 2022年, 情報処理学会研究報告(Web), 2022(DPS-190) (DPS-190)機械学習を用いた悪性TLS通信の検知と通信特徴の推移に関する考察
- 2022年, インテリジェント・システム・シンポジウム(CD-ROM), 30thプライバシー保護連合学習による組織間ビッグデータ解析とその応用
- 2022年, インテリジェント・システム・シンポジウム(CD-ROM), 30th動的サンプリングを用いた連合学習型勾配ブースティング決定木の継続学習
- 2022年, 人工知能学会第二種研究会資料(Web), 2022(FIN-028) (FIN-028)機械学習を用いたアナリストレポート分析と投資判断レーティング予測
- 2022年, 人工知能学会第二種研究会資料(Web), 2022(FIN-028) (FIN-028)投資支援のためのニュース記事からのESG関連文抽出
- 2021年, システム制御情報学会研究発表講演会講演論文集(CD-ROM), 65thスーパーセキュリティーゲートの実用化に向けた深層学習モデルの軽量化
- 2021年, 情報処理学会研究報告(Web), 2021(CSEC-92) (CSEC-92)ダークネットにおける大規模調査パケットを考慮したポート番号埋め込みベクトルによるスキャンパケット解析
- 2021年, 知能システムシンポジウム講演資料(CD-ROM), 48th (Web)物体検知および追跡手法を用いた大豆の花数計測システムの開発
- 2021年, 情報科学技術フォーラム講演論文集, 20th時系列パターンの共起性に基づく大豆の収量に関与する土壌水分環境の抽出
- 2020年, システム制御情報学会研究発表講演会講演論文集(CD-ROM), 64thスーパーセキュリティーゲート実現に向けた磁場分布画像解析の深層学習による高度化
- 2020年, システム制御情報学会研究発表講演会講演論文集(CD-ROM), 64thデータ解析におけるプライバシー保護技術とその応用
- 2020年, 情報処理学会研究報告(Web), 2020(CSEC-88) (CSEC-88)深層学習モデルを用いたコマンドログに基づくユーザなりすまし検知
- 2020年, 情報処理学会研究報告(Web), 2020(CSEC-88) (CSEC-88)深層学習モデルを用いたURLに着目したアクセスログ内の悪性Webサイト探索
- 2019年, 計測自動制御学会制御部門マルチシンポジウム(CD-ROM), 6thAI×セキュリティの現状と期待
- 2019年, システム制御情報学会研究発表講演会講演論文集(CD-ROM), 63rd相関ルール解析とダークネット解析を用いたネットワークスキャン観測の高度化
- 2019年, システム制御情報学会研究発表講演会講演論文集(CD-ROM), 63rdRetinaNetと物体追跡手法を用いた大豆生育情報の自動取得
- 2019年, 人工知能学会全国大会(Web), 33rd自己注意機構付きLSTMを用いた景況感情報に基づく金融文書の重要文抽出
- 2019年, 人工知能学会全国大会(Web), 33rd三層ニューラルネットワークにおけるRing-LWEベース準同型暗号を用いた効率的なプライバシー保護推論処理
- 2019年, 人工知能学会全国大会(Web), 33rd畳み込みニューラルネットワークを用いたアナリスト往訪記録における景況感判定
- 2019年, 電子情報通信学会技術研究報告, 118(478(ISEC2018 81-134)) (478(ISEC2018 81-134))Torクローラを用いたダークウェブにおける悪性URLの探索
- 2019年, システム制御情報学会研究発表講演会講演論文集(CD-ROM), 63rd機械学習とダークネット解析を用いたDDoS観測の高度化
- 2019年, IEEE Trans. Neural Networks Learn. Syst., 30(1) (1), 2 - 10[査読有り]
- 一般社団法人 システム制御情報学会, 2019年, システム/制御/情報, 63(2) (2), 84 - 84, 日本語[招待有り]書評論文,書評,文献紹介等
- 2018年, 日本作物学会講演会要旨集, 245th北海道における薬害によるダイズの分枝発達抑制
- 2017年, 情報処理学会シンポジウムシリーズ(CD-ROM), 2017(2) (2)ダークネットトラフィックデータの頻出パターン解析
- 2017年, 人工知能学会全国大会論文集(CD-ROM), 31st大豆の生育情報を自動取得する画像センシング手法の開発
- 2017年, 情報処理学会シンポジウムシリーズ(CD-ROM), 2017(2) (2)匿名ネットワークTorにおけるマーケット商品とセキュリティ事件との関連性に関する考察
- 2016年, 情報処理学会シンポジウムシリーズ(CD-ROM), 2016(2) (2)ダークネットトラフィックの可視化とオンライン更新によるモニタリング
- 2016年, 情報処理学会研究報告(Web), 2016(SPT-17) (SPT-17)ダークネットトラフィック解析による学習型DDoSバックスキャッタ検出システム
- 一般社団法人 システム制御情報学会, 2016年, システム/制御/情報, 60(3) (3), 120 - 125, 日本語
- 2015年, 情報処理学会シンポジウムシリーズ(CD-ROM), 2015(3) (3)ダークネットトラフィックに基づく学習型DDoS攻撃監視システムの開発
- 2015年, システム制御情報学会研究発表講演会講演論文集(CD-ROM), 59thダークネットトラフィックに基づいたDDoSバックスキャッタ判定
- システム制御情報学会, 2014年05月21日, システム制御情報学会研究発表講演会講演論文集, 58, 6p, 英語A Neural Network Model for Incremental Learning of Large-Scale Stream Data
- システム制御情報学会, 2014年05月21日, システム制御情報学会研究発表講演会講演論文集, 58, 4p, 英語Fast Online Feature Extraction Using Chunk Incremental Kernel Principal Component Analysis
- 2014年, システム制御情報学会研究発表講演会講演論文集(CD-ROM), 58thダークネットパケットに対するDDoS攻撃によるバックスキャッター判定に関する研究
- 一般社団法人 システム制御情報学会, 2014年, システム/制御/情報, 58(1) (1), 46 - 46, 日本語
- システム制御情報学会, 2013年05月15日, システム制御情報学会研究発表講演会講演論文集, 57, 3p, 英語Handling Concept Drift Using Incremental Linear Discriminant Analysis with Knowledge Transfer in Non-stationary Data Streams
- 2013年, 情報処理学会シンポジウムシリーズ(CD-ROM), 2013(4) (4)ダークネットトラフィックデータの解析によるサブネットの脆弱性判定に関する研究
- 複数のパター認識を同時または逐次的に学習する問題は,マルチタスクパターン認識問題と呼ばれる.この問題では,同一の入力に対して複数のクラスラベルが割り当てられ,システムは訓練データを学習しながら,複数の認識概念を自律的に獲得することを求められる.本研究では,タスクおよび訓練データがどちらも逐次的に与えられる追加学習の設定で,タスク変動検知機能,知識移転機能,タスクの誤分類訂正機能をもつ追加学習型ニューラルネットモデルを紹介する.一般社団法人 システム制御情報学会, 2010年, システム制御情報学会 研究発表講演会講演論文集, SCI10, 301 - 301, 日本語
- インターネットの発達により,高次元かつ大量のデータが時々刻々と蓄積されるようになった.このような環境で認識,予測,診断などを効率よく行っていくには,時間的に変化するデータ群に適応して次元削減を行い,システムの追加学習が行われる必要がある.次元削減にはオンライン型の主成分分析アルゴリズムなどが提案されている.本発表では,オンライン型主成分分析と追加学習型ニューラルネットを組み合わせた学習モデルを紹介する.一般社団法人 システム制御情報学会, 2007年, システム制御情報学会 研究発表講演会講演論文集, SCI07, 164 - 164, 日本語
- 一般社団法人 システム制御情報学会, 2005年, システム/制御/情報, 49(10) (10), 424 - 425, 日本語
- 一般社団法人 システム制御情報学会, 2005年, システム/制御/情報, 49(12) (12), 488 - 488, 日本語
- 2004年11月01日, 電気学会論文誌. C, 電子・情報・システム部門誌 = The transactions of the Institute of Electrical Engineers of Japan. C, A publication of Electronics, Information and System Society, 124(11) (11), 2201 - 2201, 日本語特集号によせて
- 公益社団法人 計測自動制御学会, 2004年09月10日, 計測と制御 = Journal of the Society of Instrument and Control Engineers, 43(9) (9), 723 - 723, 日本語
- 2003年, 実吉奨学会研究報告集, 20,27-30, 日本語独立成分分析を用いた個人性抽出に関する基礎研究その他
- 公益社団法人 計測自動制御学会, 2002年12月10日, 計測と制御 = Journal of the Society of Instrument and Control Engineers, 41(12) (12), 888 - 893, 日本語
- 2000年08月10日, 計測と制御 = Journal of the Society of Instrument and Control Engineers, 39(8) (8), 522 - 522, 日本語独立成分分析
- 一般社団法人 日本ロボット学会, 1993年01月15日, 日本ロボット学会誌, 11(1) (1), 44 - 48, 日本語
- システム制御情報学会, 1992年10月15日, システム/制御/情報 : システム制御情報学会誌 = Systems, control and information, 36(10) (10), 669 - 677, 日本語ニューラルネットワーク応用の最新動向
- 1992年10月15日, システム/制御/情報 : システム制御情報学会誌 = Systems, control and information, 36(10) (10), 679 - 679, 日本語「ニューロメール」 について
- 奈良工業高等専門学校, 1992年, 奈良工業高等専門学校研究紀要, (28) (28), p41 - 44, 日本語多モジュ-ルニュ-ラルネットの動作方程式の導出
- 奈良工業高等専門学校, 1990年, 奈良工業高等専門学校研究紀要, (26) (26), p61 - 67, 日本語パタ-ンの時間伸縮を許容する自己組織化神経回路網モデル
- 奈良工業高等専門学校, 1989年, 奈良工業高等専門学校研究紀要, (25) (25), p57 - 62, 日本語コホ-ネンネットの階層化モデルによる単音節認識
- オーム社, 2021年11月, 日本語, ISBN: 9784274227974データサイエンスの考え方 : 社会に役立つAI×データ活用のために
- 培風館, 2021年03月, 日本語, ISBN: 9784563016104データサイエンス基礎
- 共編者(共編著者), Springer, 2018年12月, 英語, ISBN: 9783030042394Neural Information Processing - 25th International Conference, ICONIP 2018, Siem Reap, Cambodia, December 13-16, 2018, Proceedings, Part VIIその他
- 共編者(共編著者), Springer, 2018年12月, 英語, ISBN: 9783030042240Neural Information Processing - 25th International Conference, ICONIP 2018, Siem Reap, Cambodia, December 13-16, 2018, Proceedings, Part VIその他
- 共編者(共編著者), Springer, 2018年12月, 英語, ISBN: 9783030042219Neural Information Processing - 25th International Conference, ICONIP 2018, Siem Reap, Cambodia, December 13-16, 2018, Proceedings, Part Vその他
- 共編者(共編著者), Springer, 2018年12月, 英語, ISBN: 9783030042127Neural Information Processing - 25th International Conference, ICONIP 2018, Siem Reap, Cambodia, December 13-16, 2018, Proceedings, Part IVその他
- 共編者(共編著者), Springer, 2018年12月, 英語, ISBN: 9783030041823Neural Information Processing - 25th International Conference, ICONIP 2018, Siem Reap, Cambodia, December 13-16, 2018, Proceedings, Part IIIその他
- 共編者(共編著者), Springer, 2018年12月, 英語, ISBN: 9783030041793Neural Information Processing - 25th International Conference, ICONIP 2018, Siem Reap, Cambodia, December 13-16, 2018, Proceedings, Part IIその他
- 共編者(共編著者), Springer, 2018年12月, 英語, ISBN: 9783030041670Neural Information Processing - 25th International Conference, ICONIP 2018, Siem Reap, Cambodia, December 13-16, 2018, Proceedings, Part Iその他
- 共編者(共編著者), Elsevier, 2018年12月, 英語INNS Conference on Big Data and Deep Learningその他
- その他, Elsevier, 2018年11月, 英語, The emergence of non-trivial embedded sensor units and cyber-physical systems and the Internet of Things has made possible the design and implementation of sophisticated applications where large amounts of real-time data are collected, possibly to constitute a big data picture as time passes. Within this framework, in-telligence mechanisms based on machine learning, neural netw, ISBN: 9780128154809Artificial Intelligence in the Age of Neural Networks and Brain Computing (Chapter 12 - Computational Intelligence in the Time of Cyber-Physical Systems and the Internet of Things)学術書
- 共編者(共編著者), Springer International Publishing AG, 2016年10月, 英語, The four volume set LNCS 9947, LNCS 9948, LNCS 9949, and LNCS 9950 constitues the proceedings of the 23rd International Conference on Neural Information Processing, ICONIP 2016, held in Kyoto, Japan, in October 2016. The 296 full papers presented were carefully reviewed and selected from 431 submissions. The 4 volumes are organized in topical sections on deep and reinforcement, ISBN: 9783319466712Neural Information Processing学術書
- Springer, 2016年, 英語, ISBN: 9783319466743Neural information processing : 23rd International Conference, ICONIP 2016, Kyoto, Japan, October 16-21, 2016, Proceedings
- 共著, IN-TECH, 2009年01月, 英語State of the Art in Face Recognition学術書
- 共著, 共立出版, 2005年12月, 日本語人工知能学辞典学術書
- 共著, Borneo Publishing Co., 2005年, 英語Neural Networks Applications in Information Technology and Web Engineering学術書
- 共著, Springer-Verlag, 2004年, 英語Neural Information Processing: Research and Development学術書
- 共著, Advanced Knowledge International, 2003年, 英語Dynamic Systems Approach for Embodiment and Sociality学術書
- 共著, 朝倉書店, 1995年, 日本語ニューラルネットと計測制御学術書
- 共著, 共立出版, 1994年, 日本語, ISBN: 4320027140ニューラルネットの基礎と応用学術書
- 電子情報通信学会 総合大会, 2025年03月, 日本語AIセキュリティと安全性評価への課題[招待有り]シンポジウム・ワークショップパネル(指名)
- 2025年暗号と情報セキュリティシンポジウム(SCIS2025), 2025年01月, 日本語プライバシー保護連合学習のための継続学習モデルの提案シンポジウム・ワークショップパネル(公募)
- The 2024 International Conference on Neural Information Processing (ICONIP2024), 2024年12月, 英語Navigating Responsible AI: Opportunities, Threats, and Ethical Boundaries[招待有り]シンポジウム・ワークショップパネル(指名)
- コンピュータセキュリティシンポジウム2024, AWS/PWS共同企画「AIガバナンスに向けた政策と技術の動向について」, 2024年10月, 日本語AIを安全に利用する技術的課題と対策[招待有り]シンポジウム・ワークショップパネル(指名)
- コンピュータセキュリティシンポジウム 2024, 2024年10月, 日本語不確実なデータラベルを前提とした機械学習によるサイバー攻撃検知のための誤ラベル訂正口頭発表(一般)
- 4th CIC-NICT Workshop, Canadian Institute for Cybersecurity, University of New Brunswick, 2024年09月, 英語ime Series Data Augmentation Using State-Space Model and Its Application to Cyber Attack Data Generation[招待有り]公開講演,セミナー,チュートリアル,講習,講義等
- Workshop on Cyber Defense and Resilience at Behaviour-Centric Cybersecurity Center (BCCC), York University, 2024年09月, 英語Time Series Data Augmentation Using State-Space Model and Its Application to Cyber Attack Data Generation[招待有り]公開講演,セミナー,チュートリアル,講習,講義等
- 情報処理学会 連続セミナー2024「情報技術の新たな地平:AIと量子が導く社会変革」, 2024年09月, 日本語AIの社会実装とセキュリティ[招待有り]公開講演,セミナー,チュートリアル,講習,講義等
- EAGLE DAY 2024, 2024年04月, 日本語組織間連合学習による社会課題への取組み[招待有り]公開講演,セミナー,チュートリアル,講習,講義等
- NICTサイバーセキュリティシンポジウム2024, 2024年02月, 日本語組織間連合学習AIによる社会課題へのチャレンジ – 銀行不正送金検知の取組み[招待有り]口頭発表(招待・特別)
- 2024年暗号と情報セキュリティシンポジウム(SCIS2024), 2024年01月, 日本語アクティブスキャンによるIoT デバイスフィンガープリントを利用したマルウェア感染端末数の推定シンポジウム・ワークショップパネル(公募)
- 2024年暗号と情報セキュリティシンポジウム(SCIS2024), 2024年01月, 日本語Cloak-Bench:大規模言語モデルによるセキュリティ分析の定量的評価方式 – フィッシングキットのクローキング検出への応用シンポジウム・ワークショップパネル(公募)
- 2023年度日本OR学会関西支部シンポジウム, 2023年12月, 日本語AIによる特殊詐欺監視[招待有り]口頭発表(招待・特別)
- The 2023 International Conference on Neural Information Processing (ICONIP2023), 2023年11月, 英語The Impact of Professional Societies in Shaping Disruptive Technologies such as Generative AI[招待有り]シンポジウム・ワークショップパネル(指名)
- Chitose International Forum on Science & Technology, 2023年09月, 日本語Privacy-Preserving Machine Learning for Big Data Analysis – How can we solve social issues using AI? -[招待有り]口頭発表(招待・特別)
- 兵庫県立農林水産技術総合センター講演, 2023年08月, 日本語データサイエンスと活用事例 〜深層学習を用いた大豆の生育情報センシング〜[招待有り]公開講演,セミナー,チュートリアル,講習,講義等
- Lecture 2 at the University of Ljubljana, 2023年03月, 英語Privacy-Preserving Machine Learning for Big Data Analysis - How can we solve social issues using AI? –“[招待有り]公開講演,セミナー,チュートリアル,講習,講義等
- Lecture 1 at the University of Ljubljana, 2023年03月, 英語Cyber Security and Its Countermeasures in AI Systems[招待有り]公開講演,セミナー,チュートリアル,講習,講義等
- 情報セキュリティ・シンポジウム(日本銀行金融研究所・情報技術研究センター), 2023年03月, 日本語機械学習とOSSのセキュリティ[招待有り]シンポジウム・ワークショップパネル(指名)
- in 2023 Symposium on Cryptography and Information Security (SCIS), 2023年01月, 英語BFL-Boost: Blockchain-based Federated Learning for Gradient Boosting to Enhance Security in Model Trainingシンポジウム・ワークショップパネル(公募)
- 2022 5th Artificial Intelligence and Cloud Computing Conference, 2022年12月, 英語Cyber Security and Its Countermeasures in AI Systems[招待有り]口頭発表(基調)
- 第10回オープンテクノフォーラム(神奈川県支部第116回 CPD講座, 2022年11月, 日本語データサイエンスの考え方 : 社会に役立つAI×データ活用のために[招待有り]公開講演,セミナー,チュートリアル,講習,講義等
- 第30回インテリジェント・システム・シンポジウム(FAN2022), 2022年09月, 日本語動的サンプリングを用いた連合学習型勾配ブースティング決定木の継続学習口頭発表(一般)
- 第30回インテリジェント・システム・シンポジウム,, 2022年09月, 日本語プライバシー保護連合学習による組織間ビッグデータ解析とその応用[招待有り]口頭発表(基調)
- 第30回インテリジェント・システム・シンポジウム(FAN2022), 2022年09月, 日本語Researcher2Vecによる研究者ネットワーク可視化システムの開発 - 神戸大学における研究DXの取組口頭発表(一般)
- MS&ADサイバーワークショップ, 2022年08月, 日本語人工知能システムにおけるサイバーセキュリティリスクとその対策[招待有り]公開講演,セミナー,チュートリアル,講習,講義等
- NVIDIA AI DAYS 2022, 2022年06月, 日本語プライバシー保護連合学習技術を活用した銀行不正送金検知[招待有り]公開講演,セミナー,チュートリアル,講習,講義等
- The APNNS/IEEE-CIS Education Forum series on Deep Learning and Artificial Intelligence Summer School 2022 (DLAI6), 2022年06月, 英語Future deep learning machines inspired by the human brain[招待有り]公開講演,セミナー,チュートリアル,講習,講義等
- 第28回人工知能学会 金融情報学研究会(SIG-FIN), 2022年03月, 日本語投資支援のためのニュース記事からのESG関連文抽出口頭発表(一般)
- 第28回人工知能学会 金融情報学研究会(SIG-FIN), 2022年03月, 日本語機械学習を用いたアナリストレポート分析と投資判断レーティング予測口頭発表(一般)
- 第96回コンピュータセキュリティ合同研究発表会 (CSEC2022), 2022年03月, 日本語機械学習を用いた悪性TLS通信の検知と通信特徴の推移に関する考察口頭発表(一般)
- 2022年 暗号と情報セキュリティシンポジウム(SCIS2022), 2022年01月, 日本語動的サンプリングを使用した勾配ブースティング決定木の連合追加学習口頭発表(一般)
- 2021 4th Artificial Intelligence and Cloud Computing Conference (AICCC 2021), 2021年12月, 英語Privacy-Preserving Machine Learning for Big Data Analysis and its potential applications[招待有り]口頭発表(基調)
- コンピュータセキュリティシンポジウム 2021, 2021年10月, 日本語HTMLタグの構造に着目したグラフ畳み込みネットワークによる悪性サイト判定口頭発表(一般)
- Computer Security Symposium 2021(CSS2021), 2021年10月, 英語Detecting Malicious Websites Based onJavaScript Content Analysis口頭発表(一般)
- コンピュータセキュリティシンポジウム 2021, 2021年10月, 日本語深層学習モデルと勾配ブースティング決定木モデルを用いたユーザなりすまし検知口頭発表(一般)
- 情報科学技術フォーラム講演論文集 (FIT), 2021年08月, 日本語時系列パターンの共起性に基づく大豆の収量に関与する土壌水分環境の抽出口頭発表(一般)
- 第65回システム制御情報学会研究発表講演会 (SCI’21), 2021年05月, 日本語スーパーセキュリティゲートの実用化に向け た深層学習モデルの軽量化口頭発表(一般)
- 第186回マルチメディア通信と分散処理・第92回コンピュータセキュリティ合同研究発表会, 2021年03月, 日本語ダークネットにおける大規模調査パケットを考慮したポート番号埋め込みベクトルによるスキャンパケット解析口頭発表(一般)
- 計測自動制御学会 第48回知能システムシンポジウム, 2021年03月, 日本語物体検知および追跡手法を用いた大豆の花数計測システムの開発口頭発表(一般)
- 日本テクノセンターAI基礎研修, 2021年02月, 日本語デジタルトランスフォーメーションで求められるAIの役割[招待有り]口頭発表(招待・特別)
- 2021年 暗号と情報セキュリティシンポジウム(SCIS2021), 2021年01月, 日本語準同型暗号を用いたプライバシー保護決定木アンサンブルによる外れ値検知口頭発表(一般)
- 2021年 暗号と情報セキュリティシンポジウム(SCIS2021), 2021年01月, 日本語文字レベル畳み込みニューラルネットによる悪性サイト判定のURL単語頻度に基づく高度化口頭発表(一般)
- Computer Security Symposium 2020 (CSS2020), 2020年10月, 英語Deep Pyramid Convolutional Neural Networks for Detecting Obfuscated Malicious JavaScript Codes Using Bytecode Sequence Features口頭発表(一般)
- コンピュータセキュリティシンポジウム 2020, 2020年10月, 日本語ポート番号埋め込みベクトルを用いたダークネットスキャンパケット解析口頭発表(一般)
- コンピュータセキュリティシンポジウム 2020, 2020年10月, 日本語協調学習スキームを導入したプライバシー保護XGBoost口頭発表(一般)
- Deep Learning and Artificial Intelligence Summer School 2020 (DLAI3), 2020年06月, 日本語An Introduction to Privacy-Preserving Machine Learning for Big Data Analysis[招待有り]口頭発表(招待・特別)
- 日本テクノセンターAI基礎研修, 2020年06月, 日本語AI基礎研修 -データ解析のためのAI-[招待有り]口頭発表(招待・特別)
- 第64回システム制御情報学会研究発表講演会 (SCI’20), 2020年05月, 日本語データ解析におけるプライバシー保護技術とその応⽤[招待有り]口頭発表(招待・特別)
- システム制御情報学会研究発表講演会講演論文集(CD-ROM), 2020年05月, 日本語スーパーセキュリティーゲート実現に向けた磁場分布画像解析の深層学習による高度化口頭発表(一般)
- 人工知能学会 第24回金融情報学研究会, 2020年03月, 日本語アナリストレポートにおけるキーワード関連文の抽出と景況感推移観測への応用口頭発表(一般)
- 情報処理学会研究報告(Web), 2020年03月, 日本語深層学習モデルを用いたURLに着目したアクセスログ内の悪性Webサイト探索口頭発表(一般)
- 情報処理学会研究報告(Web), 2020年03月深層学習モデルを用いたコマンドログに基づくユーザなりすまし検知
- KOBE×DXプロジェクト2019 DXミドルマネジメント向け講座, 2020年01月, 日本語, デジタルトランスフォーメーション研究機構, 神戸学院大学 神戸三宮サテライト, 変化の激しいビジネス環境や顧客ニーズが多様化する現在の社会では、あらゆる場面でデータの活用やデジタル技術が不可欠です。こうしたデータやデジタル技術やデータの活用については、かつてのようにITの専門家であるベンダや企業・自治体内の情報システム部門だけでなく、事業・サービスを主導するミドルマネジメント層が理解していなければ、事業の効率化やイノベーションを期待することはできません。今や業務、経営とデジタルは完全に一体となっています。 本講座は、まずデジタル技術について、その各技術の概要について簡単に触れた後、データの利活用について、事業を推進するリーダー役であるミドル層として最低限、理解しておかなければならない知識について、活用事例やデータ取得の難しさ等も含めて紹介します。特にこれからの社会やビジネスを大きく変えるであろうVRについて実際に体感し、デジタル技術を自分事として捉えられるようにします。この講座を受講することによりデジタルを活用した未来を想像し、自社ビジネスとデジタルのつながりを考えることができるようになることが期待できます。 また、本講座受講後はデータ利活用のための技術を、深い知見を有する社員や委託先とスムーズなコミュニケーションができるようになり、また、経営層に対しては意思決定に必要なデータを提供し、それを説得力のある形で説明できるレベルになることが期待できます。デジタルトランスフォーメーションがもたらす社会変革(1)『いまさら聞けないデジタル化[招待有り]公開講演,セミナー,チュートリアル,講習,講義等
- 2019 International Conference on Neural Information Processing, 2019年12月, 英語, Asia Pacific Neural Network Society (APNNS), Manly, Sydney, オーストラリア連邦, 国際会議Machine Learning Approach to Detection of Malicious URLs and JavaScript[招待有り]口頭発表(招待・特別)
- International Conference on Neural Information Processing, 2019年12月, 英語, Asia Pacific Neural Network Society (APNNS), Manly, Sydney, オーストリア共和国, 国際会議Brain-Inspired Neural Network Architectures for Brain Inspired AI[招待有り]シンポジウム・ワークショップパネル(指名)
- DX実務者入門講座(第3回), 2019年12月, 日本語, デジタルトランスフォーメーション研究機構, 神戸学院大学 神戸三宮サテライト(神戸市), 日本国, デジタル技術やデータ利活用で業務プロセスを変革し、新しいビジネスモデルを創造していくデジタルトランスフォーメーション(DX)が、いま、社会全体で求められています。現在進行しているサービスや、顧客管理におけるDXの活用事例、人工知能技術、情報セキュリティ、そしてそれらを支える統計解析や数学の基礎について、コンパクトに学べるDX入門講座を神戸三宮で開催します。6回全てご参加いただいた受講者には「受講認定証」を授与いたします。奮ってご参加ください。DXと人工知能のメカニズムと活用[招待有り]公開講演,セミナー,チュートリアル,講習,講義等
- 日本総研セミナー, 2019年11月, 日本語人工知能のメカニズムと活用[招待有り]公開講演,セミナー,チュートリアル,講習,講義等
- コンピュータセキュリティシンポジウム2019論文集, 2019年10月, 日本語Ring-LWEベース準同型暗号を用いたプライバシー保護決定木分類口頭発表(一般)
- コンピュータセキュリティシンポジウム2019論文集, 2019年10月, 日本語ダークネットUDP通信の可視化画像とトラフィック統計量を用いたDDoSバックスキャッタ判定の改善口頭発表(一般)
- Society5.0実現のためのセンシングソリューション技術分科会,JEITA,電子情報技術産業協会, 2019年08月, 日本語プライバシー保護データマイニングとデジタルトランスフォーメーション[招待有り]口頭発表(招待・特別)
- 人工知能学会全国大会(Web), 2019年06月, 日本語, 一般社団法人 人工知能学会,三層ニューラルネットワークにおけるRing-LWEベース準同型暗号を用いた効率的なプライバシー保護推論処理
データのプライバシーへの懸念が膨大なデータの利活用を妨げている.プライバシーを保護した上でデータ解析を行う技術は重要である.本研究では,Ring-LWEベースの準同型暗号を用いて三層ニューラルネットの内積演算を効率よく行えるプライバシー保護機械学習モデルを提案する.提案モデルは,入力データを暗号化して,その識別結果を受け取るクライアント,学習済モデルを用いて暗号化された入力に対する識別結果を計算するサーバで構成される.これにより,クライアントはデータのプライバシーを漏らすことなく,モデル製作者はモデルを公開することなくデータの解析を行うことができる.提案手法では,一つのクラスの推論処理に対して,10.549 [ms]の時間を要する.また,Sigmoid関数やReLU関数の場合に近い精度で推論処理を行える.
口頭発表(一般) - 人工知能学会全国大会(Web), 2019年06月, 日本語, 一般社団法人 人工知能学会,自己注意機構付きLSTMを用いた景況感情報に基づく金融文書の重要文抽出
投信会社や投資顧問のアナリストが企業を訪問し、ヒアリングした内容は往訪記録として大量に蓄積されている。これらには、企業の財務状況や将来計画など、個々の企業の投資価値を判断する重要情報が詰まっており、それらの情報を総合して、ファンドマネージャーが投資先を決断する。しかしながら、大量に蓄積された情報から適切な景況分析と投資判断を導き出すことは、熟練のファンドマネージャーであっても容易ではない。本研究では,アナリストが作成した往訪記録に対し、リカレントニューラルネットであるBidirectional LSTMで文書単位の埋め込みベクトルを求め、往訪記録に付与された景況感情報を教師信号として自己注意機構の重みに基づいた学習を行い、重要文章の抽出を行う。1,390件の往訪記録を5重交差検定法で性能評価した結果、約79%の抽出精度が得られ、トピックモデルの一つである教師ありLDAモデルに比べても高い精度が得られることを示す。
口頭発表(一般) - 人工知能学会全国大会(Web), 2019年06月, 日本語, 一般社団法人 人工知能学会,畳み込みニューラルネットワークを用いたアナリスト往訪記録における景況感判定
投資家の資金を預かり,その運用を行う運用会社では,投資対象の企業を決定するため,各企業にアナリストがヒアリングして財務状況や将来計画などの情報を収集している.この調査分析結果は往訪記録やアナリストレポートとしてまとめられ蓄積されているが,その量が膨大であるため,たとえ熟練したファンドマネージャであっても,これらから適切な投資判断を導き出すことは容易でない.そこで,本研究では,ファンドマネージャーやアナリストの調査分析にかかる労力を軽減し,企業や業界の景況感判定を適切に行えるようサポートする機械学習システムを提案する.一文書内に極性が混在するアナリスト往訪記録の特性から,可読性と極性揺らぎへのロバスト性をあわせもつと期待される畳み込みニューラルネット(CNN)を用い,往訪記録に対する景況感判定を試みる.三井住友DSアセットマネジメント株式会社から提供された往訪記録に対し,CNNによる極性分類を試みた結果,81.4%の判定精度が得られ,Word2VecやDoc2Vecなどで得られた組み込みベクトルで分類するモデルに比べて5.7%精度が向上した.
ポスター発表 - 2019 神戸大学 数理・データサイエンスセンター シンポジウム ~AIセキュリティとフィンテック応用の最前線~, 2019年05月, 日本語, 神戸大学 数理・データサイエンスセンター, 大阪イノベーションハブ, 日本国, 神戸大学 数理・データサイエンスセンターでは、機械学習やブロックチェーン技術の社会実装の推進とデジタルトランスフォーメーションに対応する人材の育成を目指し、2019年5月に一般社団法人デジタルトランスフォーメーション研究機構を設立します。今回はそのディセミネーションイベントとして、フィンテック分野におけるセキュリティをテーマにしたシンポジウムを開催し、デジタルトランスフォーメーションを推進するうえで必須のセキュリティ技術について参加者と広く情報共有・意見交換する場とすることを目指します。プライバシー保護データマイニングにより拡がるビッグデータ解析[招待有り]シンポジウム・ワークショップパネル(指名)
- 63回システム制御情報学会研究発表講演会, 2019年05月, 日本語RetinaNetと物体追跡手法を用いた大豆生育情報の自動取得口頭発表(一般)
- 63回システム制御情報学会研究発表講演会, 2019年05月, 日本語相関ルール解析とダークネット解析を用いたネットワークスキャン観測の高度化口頭発表(一般)
- 63回システム制御情報学会研究発表講演会, 2019年05月, 日本語機械学習とダークネット解析を用いたDDoS観測の高度化口頭発表(一般)
- 第6回制御部門マルチシンポジウム, 2019年03月, 日本語, SICE, 熊本大学, 深層学習や機械学習、自然言語処理などを使ったAI技術の進展は目覚ましく、画像認識や音声認識の能力では、すでに人間を上回っているとされます。しかし、セキュリティ分野での機械学習の活用には、まだ課題も多く、AIの強みと限界を知り、現実の問題に向き合いながらにうまく使っていくことが重要です。本講演では、3つのAI×セキュリティを取り上げます。一つ目は、AIをサイバー攻撃の検知や分類に活かす試みですが、そもそも攻撃に関するデータをどのように収集してAIのモデルを学習し、予測に役立てるかは自明ではありません。これは多くの実応用でAIを活用するときの共通の悩みになっており、講演の第1部では、まずこの点に着目した解説を試みます。次に、AIを守るためのセキュリティについて考えます。近年、クラウド上でAIを構築して、サービスを提供するMachine Learning, 国内会議AI×セキュリティの現状と期待[招待有り]口頭発表(招待・特別)
- 電子情報通信学会技術研究報告, 2019年, 日本語, 電子情報通信学会, 近年,Drive-by-Download攻撃やフィッシングなどのWebを媒介するサイバー攻撃が深刻化しており,ユーザを悪性サイトに誘導しない仕組みの導入が求められている。これに対し,Google Safe Browsing等のブラウザ上で悪性サイトへのアクセスをブロックする仕組みが広く使われている.WarpDriveは特定の悪性サイトをブロックするだけでなく,ユーザ参加型の観測網を構築することで,Web媒介型攻撃の実態解明と対策を目指すプロジェクトである.本研究はWarpDrive研究プロジェクトの一環として,ダークウェブに存在する未知悪性サイト情報の収集を行う仕組みを提案する.具体的にはTorネットワークから表層へのリンクをクローラによって収集し,VirusTotalとGredエンジンで悪性度判定を行うシステムを構築した.また,どのようなサイトに悪Torクローラを用いたダークウェブにおける悪性URLの探索
- 第30回AIセミナー, 2019年01月, 日本語, 産業技術総合研究所, 産総研人工知能研究センター(東京都), 深層学習や機械学習、自然言語処理などを使ったAI技術の進展は目覚ましく、画像認識や音声認識の能力では、すでに人間を上回っているとされます。しかし、セキュリティ分野での機械学習の活用には、まだ課題も多く、AIの強みと限界を知り、現実の問題に向き合いながらにうまく使っていくことが重要です。AIを使ったサイバー攻撃の検知や分類が活発に研究されていますが、近年、AI自体がサイバー攻撃の対象となることも知られており、AIをどう護るかも重要な課題になっています。一方で、セキュリティとAIを組み合わせることで、これまでにない新しいサービスへの期待も広がりつつあります。本講演では、我々の取り組みを紹介させて頂きながら、セキュリティ分野におけるAIへの期待と現状について一緒に考えたいと思います。, 国内会議セキュリティ分野におけるAI活用の現状と期待[招待有り]口頭発表(招待・特別)
- 2018 Artificial Intelligence and Cloud Computing Conference, 2018年12月, 英語, ACM Sigapore Chapter, Hotel Sunroute Plaza Shinjuku (Tokyo), Increasing the maliciousness and the diversity of cyber-attacks is one of the most concerned issues in recent years. There are various kinds of cyber-threads such as malware infection, DDoS attacks, probing to find security vulnerability, phishing, and spam mails to lure malicious web site, which intend to steal money/important information and to stop or disturb public services, 国際会議Challenges and Expectations against AI in Security[招待有り]口頭発表(基調)
- AC・Net研究会,, 2018年10月, 日本語, AC・Net, 大阪大学中之島センター(大阪市), 深層学習や機械学習、自然言語処理などを使ったAI技術が注目されていますが、これらの強みと限界を知り、現実の問題に向き合いながらに正しく使うことが重要です。サイバーセキュリティにおいて、これら「万能でないAI」をどう活かせばよいでしょうか?また、人工知能が社会実装されていく上で、AI自体がサイバー攻撃の対象となり得ることが懸念されています。これに、どう対応していけばよいのでしょうか?このような懸念と不安がくすぶりつつも、一方では、セキュリティとAIを組み合わせることで、これまでにない新しいサービスへの期待も広がりつつあります。このようなセキュリティ分野における人工知能への期待と現状について、その動向をご紹介できればと思います。, 国内会議セキュリティ分野におけるAIへの期待と現状[招待有り]口頭発表(招待・特別)
- 制御技術部会研究会講演, 2018年10月, 日本語, SICE, 東京電機大学 東京千住キャンパス(東京都), 深層学習や機械学習、自然言語処理などを使ったAI技術が注目されていますが、これらの強みと限界を知り、現実の問題に向き合いながらに正しく使うことが重要です。サイバーセキュリティにおいて、これら「万能でないAI」をどう活かせばよいでしょうか?また、人工知能が社会実装されていく上で、AI自体がサイバー攻撃の対象となり得ることが懸念されています。これに、どう対応していけばよいのでしょうか?このような懸念と不安がくすぶりつつも、一方では、セキュリティとAIを組み合わせることで、これまでにない新しいサービスへの期待も広がりつつあります。このようなセキュリティ分野における人工知能への期待と現状について、その動向をご紹介できればと思います。, 国内会議AIのAIによるAIのためのセキュリティ:セキュリティ×AIの現状と期待[招待有り]口頭発表(招待・特別)
- The 13th International Workshop on Security (IWSEC2018), 2018年09月, 英語, IWSEC, Sakura Hall, Tohoku University (仙台市), 国際会議Privacy-Preserving Naive Bayes Classifier based on Homomorphic Encryptionポスター発表
- The 13th International Workshop on Security (IWSEC2018), 2018年09月, 英語, IWSEC, Sakura Hall, Tohoku University (仙台市), Websites attracts millions of visitors due to the convenience of services they offer. These include news, entertainment and educational contents among many others. However, a large number of users frequenting these sites are considered as interesting targets for cyber attackers. These websites are injected with malicious codes by exploiting vulnerabilities in servers, plugins a, 国際会議Detection of JavaScript-based Attacks Using Doc2Vec Feature Learningポスター発表
- 日本テクノセンターセミナー, 2018年09月, 日本語, 日本テクノセンター, たかつガーデン(大阪市), AIの基礎とその限界を理解し、データや目的に応じて、どのような手法を適用したらよいかの見当をつける能力を習得できる。, 国内会議AI・機械学習における各種手法・技術と適用のポイント・事例[招待有り]口頭発表(招待・特別)
- 次世代AI技術セミナー, 2018年09月, 日本語, 兵庫エレクトロニクス研究会, 兵庫県立工業技術センター, AIとは何か?AIは使い物になるのか?AIで産業や技術はどう変わっていくのか?昨今のAIの躍進とその背景を振り返りながら、この問いに答えていきたいと思います。, 国内会議AIの躍進の背景と最新技術動向[招待有り]口頭発表(招待・特別)
- BESK Workshop, 2018年08月, 英語, BESK, Gangneung Green City Experience Center (Gangneung, Korea), 国際会議A New Direction of Machine Learning: Privacy-Preserving Data Mining (PPDM)[招待有り]口頭発表(招待・特別)
- AI Flagship Project Workshop, 2018年08月, 英語, Kyungpook National University, Gangneung–Wonju National University (Gangneung, Korea), 国際会議A Machine Learning Approach to Privacy-Preserving Data Mining Using Homomorphic Encryption[招待有り]口頭発表(招待・特別)
- SCSK講演:AIに関する基礎・将来講座, 2018年07月, 日本語, SCSK, 豊洲フロント(東京都), 機械学習や深層学習、自然言語処理などのAI技術への期待は高まるばかりですが、一方でその限界も認識されつつあります。本講演では、AIの強みと限界を知り、サイバー攻撃にどのように向き合い、活かしていくべきなのか、我々が行っている研究事例を紹介しながら考えてみたいと思います。, 国内会議サイバー攻撃対策としてのAIへの期待と現状[招待有り]口頭発表(招待・特別)
- 2018年人工知能学会全国大会, 2018年06月, 日本語, 人工知能学会, 城山ホテル(鹿児島市), スマート農業において,生育状態の自動観測は重要なタスクである.本論文では,機械学習による大豆の花と子実を検知する検知手法を提案する.また,動画から子実をカウントする新手法も提案する.我々は高速かつ高い精度を持つSingle Shot MultiBox Detectorを使用した.画像は北海道農業研究センターで2015年から2017年にかけて収集した.子実検知と花検知はそれぞれ0.586(F値)と0.646(F値)の性能を達成した., 国内会議大豆の生育情報を自動取得する画像センシング手法の開発 - Single Shot MultiBox Detectorの導入口頭発表(一般)
- 2018年AI・機械学習シンポジウム, 2018年05月, 日本語, NPO法人M2M・IoT研究会, 藤沢商工会館みなパーク (藤沢市), 深層学習や機械学習,自然言語処理などを使ったAI技術が注目されているが,これらの強みと限界を知り,現実の問題に向き合いながらに正しく使うことが重要である.機械学習のツールやライブラリーをブラックボックスとして使うのではなく,その中身を知ることで,正しい手法を正しい目的で使えるよう機械学習の基礎を講述する.また,AI技術を使った最新の応用事例を紹介する., 国内会議AI・機械学習の基礎と広がるAI応用[招待有り]口頭発表(招待・特別)
- KansAI0.6 事業開発講座, 2018年04月, 日本語, Scribble Osaka Lab, Scribble Osaka Lab (大阪市), 国内会議人工知能技術の基礎と応用[招待有り]口頭発表(招待・特別)
- The 2nd Nanyang Technological University and Kobe University Workshop on Data Science and Artificail Intelligence, 2018年03月, 英語, Nanyang Technological University, Singapore, 国際会議Collecting Cybersecurity-related Contents in Dark Webポスター発表
- AIセキュリティ最前線2018, 2018年02月, 日本語, 東京都, 国内会議万能でないAIのサイバーセキュリティでの活かし方[招待有り]公開講演,セミナー,チュートリアル,講習,講義等
- データサイエンスセミナー, 2018年02月, 日本語, 大阪市, 国内会議人工知能分野における最新の研究・技術動向[招待有り]公開講演,セミナー,チュートリアル,講習,講義等
- NICT サイバーセキュリティシンポジウム, 2018年02月, 日本語, NICT, 東京都, 国内会議機械学習によるサイバーセキュリティとプライバシー保護データマイニングへの取組み[招待有り]公開講演,セミナー,チュートリアル,講習,講義等
- 第45回SICE知能システムシンポジウム, 2018年02月, 日本語, SICE, 豊中市, 国内会議なぜ『セキュリティ×機械学習』?[招待有り]公開講演,セミナー,チュートリアル,講習,講義等
- 2018年暗号と情報セキュリティシンポジウム, 2018年01月, 英語, 電子情報通信学会, 新潟市, To add more functionality and usability to web applications, JavaScript (JS) which is a dynamic and lightweight scripting language is frequently used. However, even with its advantages and usefulness in web applications, it is problematic that there exist malicious JS codes aiming for cyberattacks such as drive-by-download attacks. In general, malicious JS code are not easy to, 国内会議Detection of Malicious JavaScript Contents Using Doc2vec Feature Learning口頭発表(一般)
- 第4回ASF次世代セキュリティシンポジウム, 2017年12月, 日本語, 東京都, 国内会議AI・機械学習の観点からの 次世代セキュリティ[招待有り]公開講演,セミナー,チュートリアル,講習,講義等
- Nanyang Technological University and Kobe University Workshop on Data Science, 2017年11月, 英語, Kobe University, 神戸市, 国内会議Recent Challenges to Cybersecurity and Privacy-Preserving Data Mining Using Machine Learning公開講演,セミナー,チュートリアル,講習,講義等
- 2nd Bilateral Workshop on Research Exchange between National Taiwan University and Kobe University, 2017年11月, 英語, National Taiwan University, Taipei, Taiwan, 国際会議A Brief Introduction to Data Science Center and Research Topics on Machine Learning for Big Data公開講演,セミナー,チュートリアル,講習,講義等
- コンピュータセキュリティシンポジウム 2017, 2017年10月, 日本語, 情報処理学会, 山形市, 国内会議匿名ネットワークTorにおけるマーケット商品とセキュリティ事件との関連性に関する考察口頭発表(一般)
- コンピュータセキュリティシンポジウム 2017, 2017年10月, 日本語, 情報処理学会, 山形市, 国内会議加法準同型暗号を用いたプライバシー保護Extreme Learning Machine口頭発表(一般)
- コンピュータセキュリティシンポジウム 2017, 2017年10月, 日本語, 情報処理学会, 山形市, 国内会議ダークネットトラフィックデータの頻出パターン解析口頭発表(一般)
- The 2017 International Seminar on Sensors, Instrumentation, Measurement and Metrology (ISSIMM2017), 2017年08月, 英語, Surabaya, Indonesia, 国際会議Challenge to Building Agricultural Cyber-Physical System for Smart Agriculture: Image Sensing Approach to Automatic Phenotyping for Soybean Plants[招待有り]公開講演,セミナー,チュートリアル,講習,講義等
- Seminar at Universitas Airlangga, 2017年08月, 英語, Surabaya, Indonesia, 国際会議A Challenge to Discover Rules from the Real World Using Big Data Analysis and Machine Learning公開講演,セミナー,チュートリアル,講習,講義等
- Seminar at Institut Teknologi Sepuluh Nopember (ITS), 2017年08月, 英語, Surabaya, Indonesia, 国際会議A Challenge to Discover Rules from the Real World Using Big Data Analysis and Machine Learning公開講演,セミナー,チュートリアル,講習,講義等
- 関西部会第4回 技術研究講演会, 2017年06月, 日本語, M2M・IoT研究会, 大阪市, 国内会議IoTとサイバーフィジカルシステムを知能化するAI技術の動向[招待有り]公開講演,セミナー,チュートリアル,講習,講義等
- 2017年度人工知能学会全国大会, 2017年05月, 日本語, 人工知能学会, 名古屋市, We propose an image sensing method to acquire the growth information (the positions and the numbers of flowers, grains and stems) automatically in the crowd of soybean plants for a smart cyber-physical system in agriculture. In our method, we combine image processing and machine learning methods to detect flowers, seeds and stems robustly and accurately. To evaluate the detecti, 国内会議大豆の生育情報を自動取得する画像センシング手法の開発口頭発表(一般)
- IJCNN2017 Post-Confence Workshop: 3rd International Workshop on Advances in Learning from with Multiple Learners (ALML 2017), 2017年05月, 英語, IEEE, Anchorage, USA, 国際会議SNS Flaming Event Detection Based on Sentiment Polarity Prediction with Transfer Learning[招待有り]シンポジウム・ワークショップパネル(指名)
- AI・機械学習における各種手法・技術と適用のポイント・事例, 2017年05月, 日本語, テクノセンター, 大阪市, コンピュータやネットワーク、携帯電話、監視カメラ、各種センサなど電子機器の普及に伴い、日々膨大な量の通信データやセンサデータが生成・蓄積されるようになりました。いわゆる「ビッグデータ」です。ビッグデータはメールやSNSなどのテキスト情報だけでなく、画像や動画、音声、各種センサ情報、顧客情報、医療情報など、様々な情報の集合体であり、一般に多様な種類の情報から構成される高次元ベクトルで表されます。このような大量かつ高次元のデータから、認識や予測、診断などを高性能に行うためには、適切な識別器(予測器)モデルを選択して学習するだけでなく、必要最小限の情報に縮約する特徴選択や特徴抽出などの技術も熟知している必要があります。 本講義では、ニューラルネットや機械学習、データマイニングでよく使われている技術をいくつか紹介し、実際の問題を取り上げて、どのようなケースで, 国内会議AI・機械学習における各種手法・技術と適用のポイント・事例[招待有り]公開講演,セミナー,チュートリアル,講習,講義等
- 第243回日本作物学会講演会, 2017年03月, 日本語, 国内会議北海道におけるフルチアセットメチルの散布がダイズの収量に及ぼす影響口頭発表(一般)
- UAB-Kobe University Joint Workshop on Smart Cyber-Physical Systems, 2017年02月, 英語, Universitat Automata de Barcelona, Barcelona, Spain, 国際会議Learning and Visualization of High-dimensional Big Data and Its Application to Cybersecurity[招待有り]シンポジウム・ワークショップパネル(指名)
- 第10回コンピューテーショナル・インテリジェンス研究会, 2016年12月, 日本語, SICE, 富山市, 農業にICT技術を用いる「スマートアグリ」が近年注目されている.スマートアグリでは農作物の育つ環境や生育情報をコンピュータで管理し,農作業の効率化を目指している.農作物の成長度合いを自動で収集し,解析することで更なる収量の増加が期待されている.子実は収量に直結する重要な生育情報として,群落内で農作物を任意の速度で昇降する単軸ロボットを用いて,下から上へと撮影した連続画像から,子実の検知を行う画像処理技術の開発を行った.本稿では農作物として大豆を扱い,一画像から子実の陰影情報より検知領域を挙げ、色情報から畳み込みニューラルネットワークを用いて検知を行う.実験には農場で撮影した画像を用い,実験結果として目視で確認した子実との比較を行った.トレーニング画像,テスト画像共にF値で80%以上の子実検知精度を得た., 国内会議大豆の子実検知を行う画像センシング手法の開発口頭発表(一般)
- 第10回コンピューテーショナル・インテリジェンス研究会, 2016年12月, 日本語, SICE, 富山市, スマート農業は,センサーから得た農作物の生育環境をコンピュータ制御により最適に保ち,収量の増加を行っている.さらなる収量の増加のため,農作物の成長の様子を表した生育情報を自動的に得ることで,データの増加を行う.花は実のできる前段階であり重要な生育情報であるとして,群落内で農作物を任意の速度で昇降する単軸ロボットを用いて,下から上へと撮影した連続画像から,花の検知と一株当たりの花数の計測を行う画像処理技術の開発を行った.本稿では農作物として大豆を扱い,領域分割と色相情報を用いて得た花候補に対して,畳込みニューラルネットワークで花であるかの判別を行い,一画像での花の検知を行う.またそれぞれの画像において,検地された花周辺でFASTを用いて特徴点を取得しORB特徴量を求め,単軸ロボットの速度と連続画像の撮影間隔から求めた連続画像内の花の移動量に基づいて対応, 国内会議大豆の花検知と花数計測を行う画像センシング手法の開発口頭発表(一般)
- 1st Bilateral Workshop on Research Exchange between National Taiwan University and Kobe University, 2016年12月, 英語, 神戸大学, 神戸市, 国内会議Recent Research on Information and Computer Science in The Department of Electrical and Electronic Engineering[招待有り]シンポジウム・ワークショップパネル(指名)
- 第9回NICTERプロジェクトワーショップ, 2016年11月, 日本語, NICT, 秋田市, 国内会議ダークネットトラフィックに基づくサイバー攻撃の分類と可視化[招待有り]シンポジウム・ワークショップパネル(指名)
- コンピュータセキュリティシンポジウム2016論文集, 2016年10月, 日本語, 情報処理学会, 秋田市, 未使用のIP アドレス空間であるダークネットには, DDoS 攻撃への返信やスキャンなど,不正な通信に伴うパケットが大量に届く.それらを観測・分析することで,インターネット上で発生している悪性な活動の動向を把握することが可能になると期待されている.本論文では,ダークネットの通信パターンの分布を可視化しモニタリングする手法を提案する.提案法では,通信パターンを特徴ベクトルとして表現し,次元圧縮することで2 次元の散布図として可視化する.また,新たな観測データが得られる毎に散布図を逐次更新することで,リアルタイムに変化を捉える.これにより,攻撃の傾向の変化や新たな攻撃の発生の検知を行うことが期待される., 国内会議ダークネットトラフィックの可視化とオンライン更新によるモニタリング口頭発表(一般)
- AI・機械学習における各種手法・技術と適用のポイント・事例, 2016年10月, 日本語, テクノセンター, 大阪市, コンピュータやネットワーク、携帯電話、監視カメラ、各種センサなど電子機器の普及に伴い、日々膨大な量の通信データやセンサデータが生成・蓄積されるようになりました。いわゆる「ビッグデータ」です。ビッグデータはメールやSNSなどのテキスト情報だけでなく、画像や動画、音声、各種センサ情報、顧客情報、医療情報など、様々な情報の集合体であり、一般に多様な種類の情報から構成される高次元ベクトルで表されます。このような大量かつ高次元のデータから、認識や予測、診断などを高性能に行うためには、適切な識別器(予測器)モデルを選択して学習するだけでなく、必要最小限の情報に縮約する特徴選択や特徴抽出などの技術も熟知している必要があります。 本講義では、ニューラルネットや機械学習、データマイニングでよく使われている技術をいくつか紹介し、実際の問題を取り上げて、どのようなケースで, 国内会議AI・機械学習における各種手法・技術と適用のポイント・事例[招待有り]公開講演,セミナー,チュートリアル,講習,講義等
- 平成28年 電気学会 電子・情報・システム部門大会, 2016年08月, 日本語, 国内会議知識獲得支援を目的とした時系列栽培データに基づく最適パターン発見口頭発表(一般)
- 平成28年 電気学会 電子・情報・システム部門大会, 2016年08月, 日本語, 国内会議時系列栽培データから抽出された最適パターンの意思決定支援への適用口頭発表(一般)
- 2016 World Congress on Computational Intelligence, 2016年06月, 英語, IEEE, Vancouver, Canada, Increasing the maliciousness and the diversity of cyber-attacks is one of the most concerned issues in recent years. There are various kinds of cyber-threads such as malware infection, DDoS attacks, probing to find security vulnerability, phishing, and spam mails to lure malicious web site, which intend to steal money/important information and to stop disturb public services, e, 国際会議Online Learning of Unstructured Data in Cybersecurity[招待有り]公開講演,セミナー,チュートリアル,講習,講義等
- Seminar at LIPN, Paris 13 University, 2016年06月, 英語, Villetaneuse, France, 国際会議Challenges to Autonomous Learning from Big Stream Data,公開講演,セミナー,チュートリアル,講習,講義等
- 60回システム制御情報学会研究発表講演会, 2016年05月, 日本語, システム制御情報学会, 京都市, The multidimensional unfolding is a data visualization technique that arranges data of different attributes in a single low-dimensional space considering the relationship between data as the distance. Emphasizing unimportant relationships, existing multidimensional unfolding method cannot preserve important relationships. In this paper, to solve this problem, we propose a metho, 国内会議確率的近傍関係を用いた多次元展開法の開発口頭発表(一般)
- 60回システム制御情報学会研究発表講演会, 2016年05月, 日本語, システム制御情報学会, 京都市, Recently, as a topic model speci cally for short texts, Biterm Topic Model was proposed. However, the original implementation uses collapsed Gibbs sampling, which is not applicable to large datasets. For faster inference, we develop stochastic collapsed variational Bayesian inference for BTM (SCVB0-BTM) based on SCVB0 for LDA. Experimental results showed that our algorithm foun, 国内会議Biterm Topic Modelの確率的崩壊型変分ベイズ推論口頭発表(一般)
- 日本作物学会第241回講演会, 2016年03月, 日本語, 国内会議北海道ダイズの収量および収量構成要素に及ぼす除草剤薬害の影響口頭発表(一般)
- 情報通信システムセキュリティ研究会, 2016年03月, 日本語, 電子情報通信学会, 京都大学, Recently, damages caused by spam mails that guide receivers to malicious web pages become more and more serious. In this study, we propose an autonomous learning system to detect such malicious spam mails. In the proposed system, the main body of a mail is transformed into a feature vector based on the tf-idf weight, and the feature vector is classi ed by machine learning class, 国内会議自律学習能力を有する悪性スパムメール検出システムシンポジウム・ワークショップパネル(公募)
- 情報通信システムセキュリティ研究会, 2016年03月, 日本語, 電子情報通信学会, 京都大学, 本研究では,ダークネットで観測されたUDP通信トラフィックからDDoS攻撃によるバックスキャッタか否かを判定するオンライン学習型の判定システムを提案する.DDoSバックスキャッタを識別するため,17の特徴量からなる特徴ベクトルを作成し,L2-SVM識別器により分類を行う.また,新たなDDoS攻撃パターンに対応するため,1クラスSVMによる外れ値検出を導入し,L2-SVM識別器の継続的な更新を行う.評価実験では,NICTのダークネットセンサで観測された半年間のパケットデータを用いて評価を行う.提案手法により,平均のF値が 0.90という高い性能でバックスキャッタ判定を行えることを示す., 国内会議ダークネットトラフィック解析による学習型DDoSバックスキャッタ検出システムシンポジウム・ワークショップパネル(公募)
- Seminar, 2016年03月, 英語, Lancaster University, Lancaster, UK, Increasing the maliciousness and the diversity of cyber-attacks is one of the most concerned issues in recent years. There are various kinds of cyber-threads such as malware infection, DDoS attacks, probing to find security vulnerability, phishing, and spam mails to lure malicious web site, which intend to steal money and important information and to stop and disturb public ser, 国際会議Learning from unstructured data stream in cybersecurity公開講演,セミナー,チュートリアル,講習,講義等
- 2016年 暗号と情報セキュリティシンポジウム, 2016年01月, 日本語, 電子情報通信学会 情報セキュリティ研究専門委員会, ANAクラウンプラザホテル熊本ニュースカイ, 特定のホストが割り当てられていないIP アドレス空間はダークネットと呼ばれる.このダークネットには,本来,パケットが到達することはないが,実際には大量のパケットが届く.それらの多くは,送信元を偽装したDDoS 攻撃に対する返信や,マルウェアによるスキャンなど,不正な活動に伴うものである.ダークネットに届くパケットを観測・分析することによって,インターネット上で発生している不正な活動の傾向を把握することが可能となる.本研究では,ダークネット観測網で得られたデータに対して,t 分布型確率的近傍埋め込み法と呼ばれる次元圧縮手法を適用し,不正活動パターンの分布を可視化した結果について報告する.この可視化により,不正活動のトレンドの把握や,新たな不正活動パターンの発生の検知などを行うことが可能になると期待される., 国内会議次元圧縮によるダークネットトラフィックデータの可視化口頭発表(一般)
- 平成27年度農林水産省委託プロジェクト「多収阻害要因の診断法及び対策技術の開発委託事業」推進会議, 2016年01月, 日本語, 農林水産省, 農林水産技術会議事務局筑波産学連携支援センター, 国内会議携帯型簡易葉色・植生測定器による大豆生育診断と低収要因の解明その他
- 計測自動制御学会 システム・情報部門学術講演会 2015, 2015年11月, 日本語, 計測自動制御学会, 函館アリーナ, 本研究では,群落画像を用いた画像センシングにより,農作物の茎の位置,草丈 を推定する手法を提案する.単軸ロボットとデジタルカメラを用いて農作物正面 から撮影した連続画像を使用し,色情報による株元検出の後,近傍領域の探索を 繰り返し茎全体の検出を行なう.また,SIFTを用いて農作物の先端の位置を検出 し,撮影位置との関係から草丈を推定する.実験では,株元が中央付近に存在する大豆の画像から株元,節,先端を検出し,検出率の評価を行なった., 国内会議画像センシングによる農作物の茎検出および草丈推定口頭発表(一般)
- 計測自動制御学会 システム・情報部門学術講演会 2015, 2015年11月, 日本語, 計測自動制御学会, 函館アリーナ, Twitter has more than 20 million users in Japan nowadays, and it is widely used as a useful communication tool, not only for personal but also for business use. On the other hand, `flaming’, which implies a soaring of negative sentiment on SNS through the diffusion of negative retweets, has been a serious problem. Main triggers of flaming incidents would be thoughtless comments, 国内会議炎上検知のためのTwitterユーザーの分類口頭発表(一般)
- NICTER Workshop, 2015年11月, 日本語, NICT, 鳴門教育大学, 国内会議ダークネットトラフィックに基づくサイバー攻撃の分類と可視化[招待有り]シンポジウム・ワークショップパネル(指名)
- 計測自動制御学会 システム・情報部門学術講演会 2015, 2015年11月, 日本語, 計測自動制御学会, 函館アリーナ, 近年,TwitterなどのSNSが急速に普及しているが,それに伴いBotアカウントの存 在が問題となっている.これは,自動的に発言する機能等が備わっており,スパムや悪意のある内容を拡散させる原因となることがあるからである.本研究では,Botを主として使用しているアカウントとそうでないアカウント (人間ユーザー)を分類する試みについて報告する.Twitterで収集した902ユーザーのツィートに対し,F値で88%の精度が得られた., 国内会議Twitterアカウントのbot判定口頭発表(一般)
- 2015 International Data Mining and Cybersecurity Workshop, 2015年11月, 英語, APNNA, Istanbul, Turkey, 国際会議Online Learning of Unstructured Data in Cybersecurity[招待有り]口頭発表(招待・特別)
- コンピュータセキュリティシンポジウム 2015, 2015年10月, 日本語, 情報処理学会 コンピュータセキュリティ研究会, 長崎ブリックホール, 本研究では,ダークネット観測網で得られたトラフィック情報からDDoS 攻撃によるバックスキャッタであるかの判定を行う学習型モニタリングシステムを提案する.パケットデータから送信元/送信先ポートや送信元/送信先IP などに関連した17 特徴を抽出し,サポートベクトルマシンによる判定を試みる.評価実験では,ルールによる判定が可能な80/TCP 以外のTCP パケットをモニタリング対象とし,DDoS バックスキャッタの判定と追加学習を行う.また,次元圧縮手法であるt 分布型確率的近傍埋め込み法を用いてホストの活動パターンの時間変化を視覚的に表し,機械学習の導入の有効性を示す./In this work, we propose a learning type monitoring system that discriminate DDoS backscatt, 国内会議ダークネットトラフィックに基づく学習型DDoS攻撃監視システムの開発口頭発表(一般)
- Kobe University Brussels European Centre Symposium, 2015年10月, 英語, 神戸大学, Brussels, Belgium, 国際会議Image Sensing Method for Smart Agriculture[招待有り]口頭発表(招待・特別)
- 第59会システム制御情報学会研究発表講演会, 2015年05月, 日本語, システム制御情報学会, 京都テルサ, In this work, we propose a method to quickly discriminate DDoS backscatter packets from those of other traffic observed by darknet sensors (i.e., backscatter or non-backscatter). For packets sent by a host during a short time, we define 17 features on packet traffic, which are then provided to an SVM classifier for classification. We apply incrimental learning to discriminate b, 国内会議ダークネットトラフィックに基づいたDDoSバックスキャッタ判定口頭発表(一般)
- 第59会システム制御情報学会研究発表講演会, 2015年05月, 日本語, システム制御情報学会, 京都テルサ, 本研究では,次元圧縮手法の一つであるt分布型確率的近傍埋め込み法(t-Distributed Stochastic Neighbor Embedding,t-SNE)について,Minimum Probability Flowと呼ばれるアルゴリズムに基づく学習法を提案する.通常の学習法では,計算量がサンプル数に対して二次のオーダーであるのに対し,提案法では線形オーダーに削減されることを示す.実験により,学習が高速化され大規模データに対してもt-SNEを適用可能となることを示す., 国内会議Minimum Probability Flowによるt分布型確率的近傍埋め込み法の高速化口頭発表(一般)
- 計測自動制御学会 第6回コンピュテーショナル・インテリジェンス研究会, 2014年12月, 日本語, 大阪, In this work, we propose an image sensing method to estimate the height of agricultural plants. In the proposed method, several images are taken by moving a digital camera attached to a single-axis robot. Then, the two consecutive images with a plant tip are automatically selected and the plant height is estimated from the two images based on the triangulation. Here, plant tips, 国内会議画像センシングによる農作物の草丈推定に関する研究口頭発表(一般)
- 第28回情報通信システムセキュリティ研究会, 2014年11月, 日本語, 一般社団法人電子情報通信学会, 宮城県仙台市, 国内会議ダークネットトラフィック観測によるDDoSバックスキャッタ判定口頭発表(一般)
- 58回システム制御情報学会研究発表講演会, 2014年05月, 日本語, 京都, Twitter は有益な情報交換ツールとして普及してきたが,その一方で個人や企業のイメージを故意に損なうことを目的とした行為も増加する傾向にある.本稿では,過度な中傷による企業イメージの毀損を防ぐため,係り受けなどの文構造だけでなく,企業名や製品名などを含んだツイートに対する経験則を取り入れたナイーブベイズ識別器を提案する.特定企業や製品名を含むツイートに対して,ネガティブツイートを78%(F-Measure),ポジティブツイートを90%の精度で識別できることを示した., 国内会議文構造と経験則に基づいたネガティブツイート識別器の提案口頭発表(一般)
- 電気学会 平成26年電気学会 電子・情報・システム部門大会, 2014年05月, 日本語, 松江, In this paper, we propose an incremental neural network model for a general class of sequential multi-task classification problems where a training data may have multiple class labels. To handle this type of classification problems, the proposed model consists of a three-layer feedforward neural network with long-term/short-term memories, and it has the following functions: one, 国内会議マルチラベル・パターン認識機能を有する逐次マルチタスク学習モデル口頭発表(一般)
- 58回システム制御情報学会研究発表講演会, 2014年05月, 日本語, 京都, In this work,we propose a method to discriminate backscatters caused by DDos attacks from normal traffic.Since the DDos attacks are imminent threats which could give serious economic damages to private companies,it is quite important to detect DDos backscatters as early as possible. To do this,11 features of port\/IP information are defined for network packets which are sent wi, 国内会議ダークネットパケットに対するDDoS攻撃によるバックスキャッター判定に関する研究口頭発表(一般)
- 58回システム制御情報学会研究発表講演会, 2014年05月, 日本語, 京都, In this research, we propose a method to analyze darknet traffic data in order to find subnetworks with security vulnerability. In general, packets reaching the darknet are considered to be generated by malwares. Thus, we can infer the vulnerability of a subnetwork by analyzing the port\/IP information of the darknet packets. To classify darknet traffic data into typical malici, 国内会議ダークネットトラフィックデータ解析によるサブネットの分類に関する研究口頭発表(一般)
- 58回システム制御情報学会研究発表講演会, 2014年05月, 英語, 京都, Kernel Principal Component Analysis (KPCA) is a widely-used feature extraction as it has been proven that KPCA is powerful in many pattern recognition problems. Considering that the conventional KPCA should decompose a kernel matrix of all training data, this would be an unrealistic assumption for data streams in real-world applications. Takeuchi et al. proposed an Incremental-, 国内会議Fast Online Feature Extraction Using Chunk Incremental Kernel Principal Component Analysis口頭発表(一般)
- 58回システム制御情報学会研究発表講演会, 2014年05月, 英語, 京都, Resource Allocating Network with Long Term Memory (RAN-LTM) can avoid the interference in incremental learning and reduce memory capacity during the learning. However, when a large set of training data are given at a time, the incremental learning in RAN-LTM can be seriously slow. A remedy for this is to select only useful data online depending on the importance of data. In thi, 国内会議A Neural Network Model for Incremental Learning of Large-Scale Stream Data口頭発表(一般)
- 暗号と情報セキュリティシンポジウム, 2014年01月, 日本語, 電子情報通信学会 情報セキュリティ研究専門委員会, 城山観光ホテル, 本稿ではスパムメールに対するオンライン悪性度判定システムを提案する. スパムメールの悪性度をオンラインで判定することで,ユーザへの悪性度別警告を発したり,悪性度の高いスパムメール送信者の特定に役立てたりすることが期待される.しかしながら,スパムメール中にURLが含まれている場合,その危険性を判断するのは一般に困難であり,さらにスパムメールの文面などは不定期に変化する.そのためブラックリスト方式で対応するのは難しい.そこで提案システムでは,教師あり学習および追加学習を用いてスパムメールの悪性度を逐次的に判定する.学習用ラベルには,クローリングシステムを利用し,特徴選択,学習,更新の3つの機能を実装する.性能評価実験では,2013年3月から8月に収集されたダブルバウンスメールを用いて,提案システムが高精度でスパムメールを逐次的に悪性度判定可能であることを, 国内会議スパムメールに対するオンライン悪性度判定システムの開発口頭発表(一般)
- 計測自動制御学会 システム・情報部門 学術講演会, 2013年11月, 日本語, 計測自動制御学会 システム・情報部門, ピアザ淡海, The developments of the high-speed machines and advanced technology services have provided the facilities for the researchers to obtain and store a large-scale stream data that are continuously generated. The biggest challenges to process the large-scale stream data are to mine useful information not only from huge amount of data but also from high dimensions, besides to provid, 国内会議A Radial Basis Function Network with Locality Sensitive Hashing for Large-Scale Stream Data口頭発表(一般)
- 計測自動制御学会 システム・情報部門 学術講演会, 2013年11月, 日本語, 計測自動制御学会 システム・情報部門, ピアザ淡海, Online feature extraction has becomes an important topic in pattern recognition. On the other hand, Kernel Principal Component Analysis (KPCA) has been known as a powerful nonlinear feature extraction. Takeuchi et al. have proposed an Incremental type of KPCA (IKPCA) where the learning is sequentially conducted for stream data. However, since the eigenvalue decomposition should, 国内会議Acceleration of Incremental Kernel Principal Component Analysis for Stream Data口頭発表(一般)
- コンピュータセキュリティシンポジウム 2013, 2013年10月, 日本語, (社)情報処理学会 コンピュータセキュリティ研究会, サンポート高松, 本研究では,NICTER darknet Dataset 2013 を用いて,マルウェアの活動を観測する,いわゆる動的解析手法の開発を行う.ダークネットとは実在しないIP アドレスのことであり,ダークネットを宛先として設定されているパケットデータは,マルウェアによるスキャン行為,感染行為,DDoS 攻撃のバックスキャッタ,設定ミスなどが考えられる.特定IP 領域(サブネット)から送出されるパケットデータをポート別に解析し,マルウェア活動を特定するとともに,その感染タイプの分析を行う.これにより,サブネットの脆弱性を判定するシステムの開発を行う., 国内会議ダークネットトラフィックデータの解析によるサブネットの脆弱性判定に関する研究口頭発表(一般)
- 第57回システム制御情報学会研究発表講演会, 2013年05月, 日本語, システム制御情報学会, 兵庫県民会館, In this work, we propose a new sequential multitask learning model that can learn training samples with multiple class labels. Since each training sample is assumed to have no task label, the proposed model must allocate each class to an appropriate task. In the proposed model, this is conducted based on the prediction errors. In addition, we introduce a new consolidation mecha, 国内会議逐次マルチタスク学習モデルのマルチラベルパターン認識への拡張口頭発表(一般)
- 第57回システム制御情報学会研究発表講演会, 2013年05月, 日本語, システム制御情報学会, 兵庫県民会館, Recently, mining knowledge from stream data such as access logs of computer, commodity distribution data and sales data, and human life-log has been attracting attention. As one of the techniques suitable for such an environment, active learning has been studied for long time. In this work, we propose a fast learning technique for neural networks by introducing Locality Sensiti, 国内会議大規模ストリームデータの高速学習に関する研究口頭発表(一般)
- 第57回システム制御情報学会研究発表講演会, 2013年05月, 日本語, システム制御情報学会, 兵庫県民会館, 国内会議樹状突起における電気特性の不均一性による情報伝播の向上口頭発表(一般)
- 第57回システム制御情報学会研究発表講演会, 2013年05月, 日本語, システム制御情報学会, 兵庫県民会館, In predicting personal emotion from tweets, it is not easy to infer the implication of personal emotion from tweets without human's intervention in the emotional analysis. This causes various difficulties in the tweet analysis in terms not only of heavy human workload, but also of keeping the consistency in the emotional evaluation by humans.To alleviate this problem, we propos, 国内会議自動インデキシングによるツィート分類に関する研究口頭発表(一般)
- 第57回システム制御情報学会研究発表講演会, 2013年05月, 日本語, システム制御情報学会, 兵庫県民会館, This study presents a method of behavior recognition of PC users using packet information. Network packets contain information on e-mails, applications, websites, etc. In this work, packet information is obtained using Wireshark (packet analyzer) and converted into a feature vector. Then, feature selections are applied to each feature vector to select important information, and, 国内会議トラフィック観測による行動認識に関する研究口頭発表(一般)
- 第57回システム制御情報学会研究発表講演会, 2013年05月, 日本語, システム制御情報学会, 兵庫県民会館, In real life, data are not always generated under stationary environments. However, traditional learning systems normally assumed that the property of data streams is stationary over time and this sometimes leads to the degradation in the system performance when there are some hidden context changes in data streams. Such context changes are called concept drift, and several app, 国内会議Handling Concept Drift Using Incremental Linear Discriminant Analysis with Knowledge Transfer in Non-stationary Data Streams口頭発表(一般)
- 平成24年電気学会電子・情報・システム部門大会, 2012年09月, 英語, 弘前大学, One of the recent topics in online learning is the adaptation to “concept drift”, in which an increasing loss of the relevance between the current data to the previous concept representations leads to imposing model changes. On the other hand, online feature extraction for high-dimensional data streams is very important to ensure high-performance and real-time adaptation to dyn, 国内会議Extension of Incremental Linear Discriminant Analysis for Online Feature Extraction under Unstationary Environments口頭発表(一般)
- 56回システム制御情報学会研究発表講演会, 2012年05月, 日本語, 京都テルサ, When the conventional incremental principal component analysis (IPCA) is used for extracting features of a data stream, IPCA has to be carried out for each of the high-dimensional input featuress; thus, the eigenvalue problem should be solved for every high-dimensional data. This may lead to the deterioration in the online performance of the feature extraction for a data stream, 国内会議実時間処理に向けた追加学習型主成分分析の高速化口頭発表(一般)
- 56回システム制御情報学会研究発表講演会, 2012年05月, 日本語, 京都テルサ, In real-world applications, concepts to be learned can sometimes be changed over time. Such a problem in machine learning is called concept drift. To adapt to the dynamic environments with concept drift, a system should have the mechanisms (1) to learn the change in the environment, (2) to detect the drift and/or its magnitude, and (3) to forget what is no longer relevant. In t, 国内会議ストリームデータの追加学習口頭発表(一般)
- 第39回知能システムシンポジウム, 2012年03月, 日本語, 計測自動制御学会, 千葉, 国内会議ストリームデータに対するカーネル主成分分析アルゴリズム口頭発表(一般)
- 電子情報通信学会技術研究報告, 2012年, 日本語, 一般社団法人電子情報通信学会, 従来の追加学習型主成分分析 (IPCA) では,訓練データが一つまたは少数ずつ与えられるたびに固有値問題を解く必要がある.一般に固有値計算は計算量が多いため,繰り返し固有値問題を解くことは,特に顔画像などの高次元データから特徴を抽出する際,学習のリアルタイム性を損なうことにつながる.そこで,本研究では,できるだけ認識性能を保ったまま, 固有値問題を解く回数を減らし,IPCA のリアルタイム実行性を高めた改良手法を提案する.逐次的に入力される顔画像データに対して,提案した改良型 CIPCA アルゴリズムがリアルタイムで主成分特徴を学習できることを示す.In the conventional Incremental Principal Component Analysis (IPCA), an eigenvalue problem has to be solved whenever one or a small number of training data are given in sequence. Since the eigenvalue decomposition requires high computational costs in general, solving the eigenvalue problem repeatedly results in the deterioration in the real-time learning property of IPCA. Hence, in this work, we propose an improved version of IPCA whose real-time learning property is enhanced without sacrificing the recognition performance by reducing the number of times to solve eigenvalue problems. We show that the improved IPCA can learn principal components real time from a stream of face images.追加学習型主成分分析の高速化と顔画像認識への応用
- 第24回自律分散システムシンポジウム, 2012年01月, 日本語, 計測自動制御学会, 神戸, 国内会議ラジアル基底関数ネットの自律追加学習アルゴリズムの改良口頭発表(一般)
- SICEシステム・情報部門学術講演会, 2011年11月, 日本語, 計測自動制御学会, 神戸, 国内会議非定常環境下でのストリームデータの追加学習方式口頭発表(一般)
- 第21回インテリジェントシステムシンポジウム, 2011年09月, 日本語, 計測自動制御学会, 神戸, 国内会議移転メトリック学習に基づいたマルチタスク学習モデルの開発口頭発表(一般)
- 第21回インテリジェントシステムシンポジウム, 2011年09月, 日本語, 計測自動制御学会, 神戸, 国内会議ラジアル基底関数ネットにおける追加型自律学習アルゴリズム口頭発表(一般)
- 第21回インテリジェントシステムシンポジウム, 2011年09月, 日本語, 計測自動制御学会, 神戸, 国内会議マルチタスクパターン認識における複数ラベルの学習口頭発表(一般)
- 電子情報通信学会ニューロコンピューティング研究会, 2011年07月, 日本語, 電子情報通信学会, 神戸, 国内会議チャンクデータに対する追加学習型カーネル主成分分析アルゴリズム口頭発表(一般)
- 55回システム制御情報学会研究発表講演会講演, 2011年05月, 日本語, システム制御情報学会, 大阪, 国内会議メトリックに基づいた知識移転を行うマルチタスク学習モデルの開発口頭発表(一般)
- 55回システム制御情報学会研究発表講演会講演, 2011年05月, 日本語, システム制御情報学会, 大阪, 国内会議マルチモーダル・マルチタスクパターン認識の追加学習方式に関する研究口頭発表(一般)
- インテリジェントシステム・シンポジウム講演論文集, 2011年, 日本語, 日本機械学会, In this paper, we propose to implement an pruning algorithm to an autonomous incremental learning model called Automated Learning algorithm for Resource Allocating Network (AL-RAN). The proposed pruning algorithm determines whether Radial Basis Functions (RBF) are useful or not by activation level of them and remove unuseful RBFs. By implementing this algorithm to AL-RAN, we reduce the number of basis and improve the learning time. From the experimental results, we confirm that the above functions work well and the efficiency in terms of learning time is improved without sacrificing the recognition accuracy as compared with the previous version of AL-RAN.1C1-1 ラジアル基底関数ネットにおける追加型自律学習アルゴリズムの改良(機械学習)
- インテリジェントシステム・シンポジウム講演論文集, 2011年, 日本語, 日本機械学会, Multi-task learning is a learning paradigm which allows a system to learn related multiple tasks in parallel or sequentially and to improve the generalization performance for a learning task by transferring the knowledge to other related tasks. In order to transfer knowledge effectively, it is necessary to estimate the relatedness between tasks properly. In this paper, we propose a multi-task learning algorithm for pattern recognition where the task relatedness is estimated based on the metric learning. Experimental results demonstrate the effectiveness of our method.1C1-3 移転メトリック学習に基づいたマルチタスク学習モデルの開発(機械学習)
- インテリジェントシステム・シンポジウム講演論文集, 2011年, 日本語, 日本機械学会, In this paper, we extend the multi-task learning (MTL) model proposed by Nishikawa et al. such that a classifier can learn training data with multiple class labels which belong to different classification tasks. In order to identify the a suitable task associated with the class of a given data, the proposed MTL model checks the prediction errors in all output sections. Then, the corresponding task is predicted from the output section with a minimum error. If all the prediction errors are large, the MTL model suspends to learn training data until the output section with a small error is found. In the experiments, we evaluate the proposed MTL model using the COIL-100 and ORL Face datasets which is extended to multi-task learning. The experimental results show that each class label given concurrently can be classified into a suitable task by the proposed system and multi-label data are efficiently learned by classifier.1B2-3 マルチタスクパターン認識における複数ラベルの学習(OS13:IRT)
- 知能システムシンポジウム資料, 2011年省メモリな追加学習型カーネル主成分分析アルゴリズム
- 知能システムシンポジウム資料, 2011年マルチタスク顔画像認識のための追加型二方向二次元線形判別分析
- SICEシステム・情報部門学術講演会, 2010年11月, 日本語, 計測自動制御学会, 京都市, 国内会議追加学習型ラジアル基底関数ネットの自律学習アルゴリズムの改良口頭発表(一般)
- SICEシステム・情報部門学術講演会, 2010年11月, 日本語, 計測自動制御学会, 京都市, 国内会議マルチタスクパターン認識におけるタスクの同時学習口頭発表(一般)
- 20回インテリジェントシステムシンポジウム, 2010年09月, 日本語, 計測自動制御学会, 八王子市, 国内会議追加学習型再帰フィッシャー判別分析によるオンライン特徴抽出口頭発表(一般)
- 平成22年電気学会電子・情報・システム部門大会, 2010年09月, 日本語, 電気学会, 熊本市, 国内会議カーネル主成分分析の高速追加学習アルゴリズム口頭発表(一般)
- 54回システム制御情報学会研究発表講演会, 2010年05月, 日本語, システム制御情報学会, 京都市, 国内会議追加学習型カーネル主成分分析アルゴリズムの改良口頭発表(一般)
- 54回システム制御情報学会研究発表講演会, 2010年05月, 日本語, システム制御情報学会, 京都市, 国内会議マルチタスク・パターン認識のための追加学習モデル口頭発表(一般)
- 知能システムシンポジウム資料, 2010年パターン認識における半教師有りマルチタスク学習モデルの開発
- 知能システムシンポジウム資料, 2010年追加学習型ラジアル基底関数ネットの自律学習アルゴリズムの開発
- システム制御情報学会研究発表講演会講演論文集(CD-ROM), 2009年, 一般社団法人 システム制御情報学会, 従来の線形判別分析(LDA)による特徴抽出では,得られる特徴ベクトルの次元は訓練データのクラス数未満で制限される.これに対し,再帰的フィッシャー判別分析(RFLD)では,LDA特徴空間の補空間に対して再帰的にLDAを行うことで,クラス数の制限を越えて任意の次元の特徴ベクトルが得られる.一方,LDAを追加学習環境に拡張した追加型線形判別分析(ILDA)がPangらによって提案されている.本研究では,ILDAの導出法に基づきRFLDを追加学習可能なように拡張し,クラス分離度に基づいて最適な特徴数を決定する方法を導入した追加型再帰的フィッシャー判別分析を提案する.この学習アルゴリズムでは,過去の訓練データを保持することなく特徴空間の更新を行うことが可能であり,クラス数以上の特徴数を得ることができる.ベンチマークデータを用いた計算機実験を通して,ILDAとの比較を行い,IRFLDはいくつかのデータにおいてILDAを超える性能を有することを示す.追加型再帰的フィッシャー判別分析の開発
- 電気関係学会関西支部連合大会講演論文集(CD-ROM), 2009年特徴抽出と識別器を追加学習するマルチタスク・パターン認識モデルの提案
- 電気学会電子・情報・システム部門大会講演論文集(CD-ROM), 2009年追加型再帰フィッシャー判別による認識性能のオンライン改善
- 電気学会論文誌 C, 2009年, 日本語, 一般社団法人 電気学会, A macro-action is a typical series of useful actions that brings high expected rewards to an agent. Murata et al. have proposed an Actor-Critic model which can generate macro-actions automatically based on the information on state values and visiting frequency of states. However, their model has not assumed that generated macro-actions are utilized for leaning different tasks. In this paper, we extend the Murata's model such that generated macro-actions can help an agent learn an optimal policy quickly in multi-task Grid-World (MTGW) maze problems. The proposed model is applied to two MTGW problems, each of which consists of six different maze tasks. From the experimental results, it is concluded that the proposed model could speed up learning if macro-actions are generated in the so-called correlated regions.Grid-World迷路問題においてマクロアクション生成機能を有する強化学習モデルとその学習特性に関する考察
- 自律分散システム・シンポジウム, 2009年01月, 日本語, 計測自動制御学会, 鳥取市, 国内会議追加学習型主成分分析における寄与率閾値の動的決定法口頭発表(一般)
- 自律分散システム・シンポジウム, 2009年01月, 日本語, 計測自動制御学会, 鳥取市, 国内会議RBFネットワークの自動追加学習アルゴリズム口頭発表(一般)
- SICE Annual Conf. 2008, 2008年08月, 英語, 計測自動制御学会, 府中市,東京都, 国内会議An Incremental Principal Component Analysis Based on Dynamic Accumulation Ratio口頭発表(一般)
- システム制御情報学会研究発表講演会, 2008年05月, 日本語, 京都市, 国内会議追加学習型主成分分析の改良口頭発表(一般)
- システム制御情報学会研究発表講演会, 2008年05月, 日本語, システム制御情報学会, 京都市, 国内会議マクロアクションの導入による強化学習の高速化口頭発表(一般)
- 平成19年電気関係学会関西支部連合大会, 2007年11月, 日本語, 神戸大学, 国内会議特徴選択による追加学習型カーネル主成分分析の高速化とその性能評価ポスター発表
- 平成19年電気関係学会関西支部連合大会, 2007年11月, 日本語, 神戸大学, 国内会議マクロアクション生成機能を有する強化学習アルゴリズム口頭発表(一般)
- 平成19年電気学会電子・情報・システム部門大会, 2007年09月, 日本語, 電気学会, 大阪府立大学, 国内会議追加学習型カーネル主成分分析の開発とその性能評価口頭発表(一般)
- 平成19年電気学会電子・情報・システム部門大会, 2007年09月, 日本語, 電気学会, 大阪府立大学, 国内会議逐次マルチタスク・パターン認識におけるタスク間関連度を用いた知識移転アルゴリズム口頭発表(一般)
- 平成19年電気学会電子・情報・システム部門大会講演論文集, 2007年09月, 日本語, 電気学会, 大阪府立大学, 国内会議マクロアクション生成機能を有する強化学習エージェントモデル口頭発表(一般)
- SICE Annual Conference, 2007年09月, 英語, 計測自動制御学会, 香川大学, 国内会議An Online Face Recognition System with Incremental Learning Ability口頭発表(一般)
- 51回システム制御情報学会研究発表講演会, 2007年05月, 日本語, システム制御情報学会, 京都テルサ, 国内会議追加学習型カーネル主成分分析の開発口頭発表(一般)
- 51回システム制御情報学会研究発表講演会, 2007年05月, 日本語, システム制御情報学会, 京都テルサ, 国内会議逐次マルチタスク学習における選択的知識移転に関する基礎的研究口頭発表(一般)
- 51回システム制御情報学会研究発表講演会, 2007年05月, 日本語, システム制御情報学会, 京都テルサ, 国内会議オンライン型特徴選択とニューラルネットの追加学習口頭発表(一般)
- 平成18年電気関係学会関西支部連合大会, 2006年11月, 日本語, 電気学会, 大阪工業大学, 国内会議追加学習型ブースティング識別器の開発口頭発表(一般)
- 平成18年電気関係学会関西支部連合大会, 2006年11月, 日本語, 電気学会, 大阪工業大学, 国内会議追加学習型カーネル主成分分析の評価口頭発表(一般)
- 第49回自動制御連合講演会, 2006年11月, 日本語, システム制御情報学会, 機械学会, 計測自動制御学会, 神戸大学, 国内会議マクロアクション生成による強化学習の高速化口頭発表(一般)
- 第49回自動制御連合講演会, 2006年11月, 英語, システム制御情報学会, 機械学会, 計測自動制御学会, 神戸大学, 国内会議A Multi-task Learning Algorithm for Pattern Recognition口頭発表(一般)
- 50回システム制御情報学会研究発表講演会, 2006年05月, 日本語, システム制御情報学会, 京都テルサ, 国内会議ブースティング識別器の追加学習に関する研究口頭発表(一般)
- システム制御情報学会研究発表講演会講演論文集, 2006年, 一般社団法人 システム制御情報学会, 近年,自動文字認識システムはあらゆる環境で有用であり,車両認知・郵便番号認識・手書き文字の文書化など広く活用・研究されている.本論文では,マレーシアのライセンスプレート文字認識を提案する.まず,車両進入時の動画像から車両領域を抽出し,プレート位置を特定.そして,ニューラルネットワークをベースにした文字認識手法を使い,車両情報を取得する.今回はシミュレーション上での本システムの結果を報告する.マレーシアライセンスプレート文字認識
- 49回システム制御情報学会研究発表講演会, 2005年05月, 日本語, システム制御情報学会, 京都テルサ, 国内会議Committee Machineの追加学習アルゴリズム口頭発表(一般)
- 第32回知能システムシンポジウム, 2005年03月, 日本語, 計測自動制御学会 システム・情報部門, 京都工芸繊維大学, 国内会議カーネルパラメータの選択メカニズムをもつブースティングカーネル判別分析法口頭発表(一般)
- 第17回自立分散システム・シンポジウム, 2005年, 日本語, 計測自動制御学会 システム・情報部門, 未記入, 国内会議マクロアクション生成機能をもつメモリベース強化学習アルゴリズム口頭発表(一般)
- 48回システム制御情報学会研究発表講演会, 2004年05月, 日本語, システム制御情報学会, 京都テルサ, 国内会議特徴空間のオンライン学習に関する研究口頭発表(一般)
- 48回システム制御情報学会研究発表講演会, 2004年05月, 日本語, システム制御情報学会, 京都テルサ, 国内会議追加学習可能な顔認識システムとその性能改善口頭発表(一般)
- 48回システム制御情報学会研究発表講演会, 2004年05月, 日本語, システム制御情報学会, 京都テルサ, 国内会議RBFネットワークを用いたメモリベース強化学習アルゴリズム口頭発表(一般)
- 第16回自律分散システムシンポジウム, 2004年, 日本語, 計測自動制御学会 システム・情報部門, 京都テルサ, 国内会議動的環境下で追加学習可能なニューラルネットモデル口頭発表(一般)
- 第16回自律分散システムシンポジウム, 2004年, 日本語, 計測自動制御学会 システム・情報部門, 京都テルサ, 国内会議ラジアル基底関数ネットのメモリベース追加学習口頭発表(一般)
- 平成15年度電気関係学会関西支部連合大会, 2004年, 日本語, 電気関係学会関西支部, 未記入, 国内会議ニューラルネットの追加学習とその応用口頭発表(一般)
- 第30回知能システムシンポジウム, 2003年03月, 日本語, 計測自動制御学会 システム・情報部門, 学術総合センター, 国内会議長期記憶をもつニューラルネットワークによる動的環境下での教師あり学習その他
- システム制御情報学会 研究発表講演会講演論文集, 2003年, 一般社団法人 システム制御情報学会, Applications of independent component analysis (ICA) to feature extraction have been a topic of research interest. Here, we propose a novel recognition method using features extracted by ICA. The proposed method consists of some modules for each category and a synthesizer. A module has a feature extraction and a classification. Features are independent components extracted by ICA algorithm using the training data for each class and classification are made by these features. These output of the module are combined and categories are decided by a majority rule. We evaluate the performance of the proposed method for several recognition tasks. From these results, we confirm the effectiveness of the recognition method using independent components for each class.クラス毎の独立成分を用いたパターン認識に関する検討
- システム制御情報学会 研究発表講演会講演論文集, 2003年, 一般社団法人 システム制御情報学会, 干渉を抑制しながら追加学習を安定に行うRBFネットワークモデルとして,これまでResource Allocating Network (RAN)に長期記憶を導入したRAN with Long-Term Memory (RAN-LTM)を提案してきた.本稿では,生成された記憶アイテムの修正メカニズムを導入した改良モデルを提案し,その干渉抑制能力と省メモリ特性について,いくつかのシミュレーション実験を通して評価する.記憶メカニズムを導入したニューラルネットによる強化学習
- システム制御情報学会 研究発表講演会講演論文集, 2003年, 一般社団法人 システム制御情報学会, As an incremental learning model, we have proposed Resource Allocating Network with Long Term Memory (RAN-LTM). In RAN-LTM, not only a new training sample but also some memory items stored in Long-Term Memory are trained based on a gradient descent method. The gradient descent method is generally slow and tends to be fallen into local minima. To improve these problems, we propose a fast incremental learning of RAN-LTM based on the linear method. In this algorithm, centers of basis functions are not trained but selected based on the output errors. A distinctive feature of the proposed model is that this model dose not need so much memory capacity. To evaluate the performance of our proposed model, we apply it to some function approximation problems. From the experimental results, it is verified that the proposed model can learn fast and accurately unless incremental learning is conducted over a long period of time.追加学習機能を有するRBFネットワークの学習高速法
- 第47回システム制御情報学会研究発表講演会, 613-614, 2003年, 日本語, システム制御情報学会, 京都テルサ, 国内会議追加学習機能を有するRBFネットワークの高速学習法口頭発表(一般)
- 第47回システム制御情報学会研究発表講演会,531-532, 2003年, 日本語, システム制御情報学会, 京都テルサ, 国内会議追加学習機能を有するRBFネットワークの高速学習法口頭発表(一般)
- 第47回システム制御情報学会研究発表講演会, 471-472, 2003年, 日本語, システム制御情報学会, 京都テルサ, 国内会議長期記憶を有するニューラルネットワークによる動的環境への適応口頭発表(一般)
- 第46回自動制御連合講演会, 2003年, 日本語, システム制御情報学会, 岡山大学, 国内会議顔画像認識に基づく追加学習型個人認証システムに関する研究口頭発表(一般)
- SICE Annual Conf. 2003, 2003年, 英語, 未記入, 未記入, 国内会議A Reinforcement Learning Algorithm for a Class of Dynamical Environments Using Neural Networks.口頭発表(一般)
- 電子情報通信学会技術研究報告. CAS, 回路とシステム, 2002年11月, 日本語, 一般社団法人電子情報通信学会, 独立成分分析(ICA)は,これまで主にブラインド信号分離問題に適用されてきたが,パターン認識の特徴抽出手法としても,一部の問題においてその有効性が示されつつある.しかしながら,従来のICAアルゴリズムによって抽出された特徴量では,その有効性が特徴空間上でパターンの分布に大きく依存する.これは,与えれているクラス情報を利用せず,単に特徴量の独立性を高めることで特徴抽出を行っていることに起因すると考えられる.そこで本稿では,特徴量の独立性を高めるだけでなく,異なるクラスに属するパターンの特徴量ができるだけ分離するよう,特徴量間のマハラノビス距離を最大化するICAアルゴリズムを提案する.この提案アルゴリズムの有効性を検証するため,UCI Machine Learning Repositoryに含まれる3種類のデータセットに対し,特徴量の有効性を認識実験で調べる.そして,ICAにクラス情報を導入することで,異なるクラスに属する特徴の分離性が向上し,認識率が改善されることを示す.また,単にマハラノビス距離を最大化する手法よりも,独立性を同時に高めることによって,より優れた特徴量が得られることを示す.クラス間距離を最大化する教師あり独立成分分析アルゴリズムの提案
- 知能システムシンポジウム資料, 2002年03月, 日本語追加学習機能をもつニューラルネットを用いた行動価値関数の近似
- 計測自動制御学会 部門大会/部門学術講演会資料, 2002年, 公益社団法人 計測自動制御学会, In reinforcement learning, forgetting by incremental learning can be serious when neural networks are utilized for approximating action-value functions of agents. To avoid the forgetting, we present a feedforward neural network model with long-term memories and its reinforcement learning algorithm. In the simulations, we apply our model to an extended mountain-car task, and the number of steps to the goal is evaluated as compared with a neural network without long-term memories. As a result, we demonstrate that the forgetting is effectively suppressed in the proposed model.追加学習能力を有するニューラルネットとその強化学習アルゴリズム
- 計測自動制御学会 部門大会/部門学術講演会資料, 2002年, 公益社団法人 計測自動制御学会, There are some studies about applications of independent component analysis (ICA) to feature extractions in pattern recognition. Since the ICA is an unsupervised learning, independent components are not always useful features for recognition. Therefore, we propose an ICA using a category information. The proposed ICA is realized by three-layered neural networks of which learning algorithm is combination of the error back-propagated algorithm and the fast ICA algorithm. Simulations are performed for three databases from the UCI database to evaluate the effectiveness of the proposed algorithm. We obtain higher recognition accuracy than the original ICA.分類情報を付加した独立成分分析による特徴抽出
- 計測自動制御学会 部門大会/部門学術講演会資料, 2002年, 公益社団法人 計測自動制御学会, We propose a new recognition method using independent components based on a subspace method. Independent components are calculated by the ensemble learning that can reduce redundant basis functions. The proposed method has some modules for each class and a combiner. A module consists of feature extraction and classification. Features are extracted by the ensemble learning and classification is made on k nearest neighbors. Outputs of modules are combined in the combiner and a category is decided by a majority rule. Simulations are performed for hand-written characters to evaluate the proposed method. Results show the effectiveness of the proposed method.クラス毎のアンサンブル学習による独立成分を用いた認識方法の提案
- Dynamics and Design Conference : 機械力学・計測制御講演論文集 : D & D, 2001年08月, 日本語, 一般社団法人日本機械学会, It is important to detect the leakage of the gas to be flammable or poisonous from the cracks in pipes of chemical plants. We examined the application of modular neural networks to the detection of the leakage sound. The modular neural network has the ability to adapt its structure according to the environment. Experiments were performed for an artificial gas leakage device with various experimental conditions for a long term. The discrimination accuracy with the proposed network was about 93%, which was better than 83% with the simple network. From the results, we confirmed the effectiveness for the application of the modular neural network to the detection of the leakage sound for the practical use.210 変化する環境下での漏洩音の検出方法(信号処理)(OS.02 : 計測・信号処理・異常診断)
- Dynamics and Design Conference : 機械力学・計測制御講演論文集 : D & D, 2000年09月, 日本語, 一般社団法人日本機械学会, We describe what characteristics an independent component analysis can extract from leakage sounds. The learning algorithm of a network was an information-maximization approach proposed by Bell and Sejnowski. We applied the independent component analysis to the leakage sound. After the learning, most of the basis functions that are columns of a mixing matrix were localized in frequency. Furthermore, there were some basis functions to extract the feature of leakage sound. From these results, we confirmed that the application of independent component analysis to the signal processing of the acoustic signal was effective.458 独立成分分析による漏洩音の検出
- 知能システムシンポジウム資料, 2000年03月, 日本語長期記憶メカニズムを導入したニューラルネットの追加学習
- 知能システムシンポジウム資料, 2000年03月, 日本語独立成分分析による音声・音響信号処理の検討
- インテリジェント・システム・シンポジウム講演論文集 = FAN Symposium : fuzzy, artificial intelligence, neural networks and computational intelligence, 1999年10月, 日本語独立成分分析を用いた文字パターンの特徴抽出
- インテリジェント・システム・シンポジウム講演論文集 = FAN Symposium : fuzzy, artificial intelligence, neural networks and computational intelligence, 1997年11月, 日本語クロス結合ホップフィールドネットから導出される自己想起型連想記憶モデルとその連想特性
- 日本神経回路学会全国大会講演論文集 = Annual conference of Japanese Neural Network Society, 1997年11月, 日本語一般化逆行列型自己想起連想記憶モデルの改良とそのダイナミックスの特徴
- インテリジェント・システム・シンポジウム講演論文集 = FAN Symposium : fuzzy, artificial intelligence, neural networks and computational intelligence, 1996年10月, 日本語遺伝的アルゴリズムを用いたモジュール構造ニューラルネットの構造決定
- 情報処理学会2020年06月 - 現在
- ACM2018年01月 - 現在
- Asia Pacific Neural Network Society (APNNS)2016年01月 - 現在
- International Neural Network Society (INNS)2015年03月 - 現在
- IEEE2001年01月 - 現在
- 人工知能学会
- 日本神経回路学会
- システム制御情報学会
- 電子情報通信学会
- 計測自動制御学会
- 日本学術振興会, 科学研究費助成事業, 基盤研究(B), 神戸大学, 2025年04月01日 - 2029年03月31日機械学習とドメイン知識を導入した攻撃データ生成技術と攻撃検知・防御の高度化
- 日本学術振興会, 科学研究費助成事業 基盤研究(A), 基盤研究(A), 神戸大学, 2022年04月01日 - 2027年03月31日スマートグラスAIのためのプライバシ制御技術本年度は、工学、社会科学の研究者の連携により、スマートグラスAI普及における将来のプライバシ要求を明らかにした。いくつかの具体的な応用を考え、プライバシ問題を検討すると同時にいくつかのプロトタイプシステムを実現し要求事項を抽出した。研究統括とメタAI(担当:塚本)については、システム全体の統括エンジンを作るために、問題分析及びシステム設計を行った。状況認識機構(担当:寺田)については、実世界での周辺・自己状況を認識するための要件を抽出しいくつかの認識機構を実装した。制御可能AIシステム(担当:小澤)については、プライバシに関わるAIの機能を制御し説明できるAIを作るために機構の設計を行った。プライバシ機構(担当:森井)については、プライバシを守るためのメカニズム構築のために、アプリケーションイメージ及びシステム要件を明確にした。科学技術社会的観点からの分析(担当:塚原)については、上記のアプリケーションイメージの具体化の中で社会の中での技術の使い方やあり方を考えた。心理的観点からの分析(担当:喜多)については、上記アプリケーションイメージの中で使う側、使われる側の心理を考えた。哲学・倫理的観点からの分析(担当:新川)については、上記のアプリケーションイメージの中でプライバシがどうあるべきかを考えた。 さらに年度後半のChatGPTやGPT-4などの大規模言語モデル(LLM)の出現によりAI技術が急速 に進歩したことで前提条件が根底から変化することから、全般的な計画の見直しを行った。 同時に、社会問題、倫理問題を体系化し、ガイドライン策定に向けた組織作りと運営方法を検討した。また、メンバー以外の人を交えたワークショップを複数回開催した。さらに講演会等で積極的にプロジェクトの紹介を行うとともに、プロジェクトのホームページとYouTubeチャンネルを立ち上げた。
- 日本学術振興会, 科学研究費助成事業 国際共同研究加速基金(国際共同研究強化(B)), 国際共同研究加速基金(国際共同研究強化(B)), 神戸大学, 2021年10月 - 2027年03月機械学習とドメイン知識を用いたサイバー攻撃生成過程モデルの精緻化本研究では、防御側の観測・検知を回避・無効化する攻撃の仕組みなど、ドメイン知識を有する専門家と国際連携体制を築き、観測のみに頼るリアクティブな対策だけでなく、新たな攻撃への予測と迅速な対応を行うプロアクティブなセキュリティ対策の構築を目指している。本年度は海外渡航が不可能であったため、国内チームの吉岡(横国大)、班(NICT)、金、小澤(神戸大)と以下の研究を実施した。
1)小澤、班、金は、URL文字列から悪性が疑われるWebサイトのHTMLコンテンツを取得し、それぞれのHTMLタグ階層構造(DOM)をグラフ表現し、それをgraph2vecで埋め込みベクトルに変換して、正規サイトを装うフィッシングサイトを見つける方法を提案した。PhishTankとOpenPhishのフィッシングサイト151件を用いた実験では、80%のフィッシングサイトがクラスタを形成し、これらクラスタが共通してもつ外部リンクから正規サイトを特定したところ、AmazonとFacebookを騙るフィッシングサイト群を見つけた。また、VirusTotalで取得可能なドメインのWhois情報、レビュー情報、DNSレコード、SSL証明書情報などを特徴量として機械学習で悪性判定する方法を提案した。その結果、1550サイトに対し、フィッシングサイトは88%、マルウェアホストサイトは91%の精度で検知できた。
2)吉岡は、WarpDrive実証実験に参加している508ユーザが受信したSMS、合計23,133件(良性 22,800件、悪性333件)を調べたところ、SMSを多く受信するユーザが悪性SMSを受信しやすいわけではなく、現時点では、攻撃者はランダムに悪性SMSを送付していることが推測された。また、悪性SMSは深夜と早朝には送られず、午後2時から5時の期間に集中していることがわかった。 - 日本学術振興会, 科学研究費助成事業 基盤研究(A), 基盤研究(A), 神戸大学, 2022年04月01日 - 2026年03月31日細胞外小胞を用いたリキッドバイオプシーによる癌に対する術前化学療法の効果予測
- 国立研究開発法人情報通信研究機構, 高度通信・放送研究開発委託研究, 国立大学法人神戸大学, 2023年02月 - 2025年03月, 研究代表者プライバシー保護連合学習の高度化に 関する研究開発 - 継続実運用に資する不正取引モニタリ ングに向けたプライバシー保護連合 学習の高度化 -
- 科学技術振興機構, AIP加速課題, 2022年04月 - 2025年03月, 研究分担者秘匿計算による安全な組織間データ連携技術の社会実装
- 日本学術振興会, 科学研究費助成事業 基盤研究(B), 基盤研究(B), 神戸大学, 2021年04月 - 2025年03月機械学習とドメイン知識を導入した攻撃生成過程のモデル化と実データによる検証
- 日本学術振興会, 科学研究費助成事業 基盤研究(C), 基盤研究(C), 国立研究開発法人情報通信研究機構, 2020年04月01日 - 2024年03月31日異業種データマイニング向けプライバシー保護機械学習メカニズムに関する研究開発課題1.「セキュアなクラウド・エッジコンピューティングに関する研究」の子課題「準同型計算と大小比較の融合」に取り組み、プライバシー保護データマイニングに活用されるセキュアな大小比較アプローチについて研究し、効率性、安全性、及び柔軟性を向上させるために、従来研究の最も効率がよいセキュアな大小比較アプローチSK17を改良した3つの方式を提案した。その中で、Efficiency-enhanced提案方式は既存方式SK17より50%程度で効率化を実現した;Security-enhanced提案方式はデータ所有者とクラウドサーバの間Oneランド通信(非対話型)で暗号化したまま大小比較の結果計算でき、サーバからデータを完全に守るより高い安全性を実現した。成果は国際会議The 23rd International Conference on Network-Based Information Systems(NBiS2020)発表した。 課題2.「プライバシー保護しつつ直・並列学習メカニズムの設計」の子課題「同・異業種データを柔軟に処理可能な直・並列学習メカニズムの提案」に取り組み、プライバシー保護決定木推測の効率化アプローチを提案した。提案手法は同業種か異業種かにも関わらず、適用可能であるので、汎用性がある。また、決定木の各ノードで分岐する時、クラウドサーバ経由で特徴値と閾値の大小比較を計算しなければいけないので、上記のEfficiency-enhancedセキュアな大小比較提案方式を利用した。成果は論文誌投稿中。
- 国立研究開発法人科学技術振興機構, 戦略的創造研究推進事業 (CREST), 国立大学法人 神戸大学, 2019年04月 - 2022年03月, 研究分担者プライバシー保護データ解析技術の社会実装競争的資金
- 国立研究開発法 人情報通信研究機構, NICT委託研究, 神戸大学, 2016年10月 - 2021年03月, 研究分担者Web媒介型攻撃対策技術の実用化に向けた研究開発
- 日本学術振興会, 科学研究費助成事業 基盤研究(B), 基盤研究(B), 神戸大学, 2016年04月 - 2020年03月, 研究代表者H28 年度では,ダークネットで観測される通信トラフィックからサイバー攻撃の検知・分類・可視化が可能となるよう,機械学習を導入した(1)検知・分類方式と(2)可視化方式の開発に取り組んだ.
(1)については,TCP通信とUDP通信のトラフィック特徴に対して独立した外れ値検出(L1-SVM)とL2-SVM識別器を組み合わせたハイブリッド型DDoS 攻撃検知システムを開発し,2016年1月1日から同年12月31日までにNICTのダークネットセンサで観測されたトラフィックデータをオンライン学習し,DDoS攻撃判定を行った.なお,ダークネットトラフィックを特徴ベクトルに変換する際に使う時間窓を30秒から1時間までの複数個設定し,1ホスト当たりの特徴ベクトル数を増やして,多様な攻撃パターンに対応できるよう改良した.その結果,1年間にわたる平均オンライン性能は,適合率0.94, 再現率0.93,F値0.93となり,安定して高精度にDDoS判定が行えることを実証した.また,識別器モデルに線形L2-SVM,k近傍法,ランダムフォレスト,RBFネットワークを導入した場合の性能を調べ,非線形L2-SVMの優位性を検証した.また,FP-Treeと呼ばれる連想ルールマイニング手法を適用し,2016年度9月下旬以降に大流行したIoTマルウェアMiraiと疑われる挙動を捉え,大流行以前の挙動と9月下旬のソースコード公開以後の挙動とに特徴的な違いがあることを発見した.
(2)については,t-SNEと呼ばれる可視化手法において,いったん得られた解を新たな初期に設定してオンラインで2次元マップを更新する方法を提案した.2014年2月1日のデータを用いて,1時間ごとにt-SNEによる可視化結果を求めたところ,DDoS攻撃を受けたホストの変化が捉えられ,DDoS攻撃以外の攻撃が新たに出現する様子などが観測された.競争的資金 - 農林水産技術会議, 戦略的プロジェクト研究推進事業, 神戸大学, 2015年04月 - 2020年03月, 研究分担者多収阻害要因の診断法及び対策技術の開発
- 国立研究開発法人科学技術振興機構, 戦略的創造研究推進事業(CREST), 国立大学法人 神戸大学, 2016年10月 - 2019年03月, 研究分担者複数組織データ利活用を促進するプライバシー保護データマイニング競争的資金
- 日本学術振興会, 科学研究費助成事業 基盤研究(C), 基盤研究(C), 神戸大学, 2012年04月 - 2015年03月, 研究代表者本研究では,マルウェア感染を誘導する悪性スパム攻撃からネットユーザを守り,マルウェアなどによる悪意ある活動を広域的に観測するため,機械学習を導入した3つの学習型システムを開発した.一つは悪性度の高いスパムメールを自動収集し,クローラ型ウェブ解析システムによる自動ラベリングとオンライン学習可能な悪性スパム検知システムである.二つ目は,未使用IP群であるダークネットへのパケットを収集し,そのトラフィック特徴をクラスタリングすることで,サブネットのマルウェア感染状況を広域監視するシステムである.最後は,ダークネットトラフィックの特徴からDDoS攻撃のバックスキャッタを判定する広域監視システムである.競争的資金
- 二国間交流事業(韓国との共同研究), 2012年, 研究代表者二国間交流「マルチモーダル・マルチタスク個人認証システムの開発」競争的資金
- 二国間交流事業(韓国との共同研究), 2011年, 研究代表者二国間交流「マルチモーダル・マルチタスク個人認証システムの開発」競争的資金
- 日本学術振興会, 科学研究費助成事業 基盤研究(C), 基盤研究(C), 神戸大学, 2008年 - 2010年, 研究代表者互いに関連性をもつ複数のパターン認識タスクを逐次的に学習する環境において,特定タスクの知識を別のタスクに「知識移転」することで,少ない訓練データで効率よく学習できることが知られている.本研究では,パターン認識の問題において,有効な特徴量を抽出する特徴空間を知識として,その知識の一部を未知の認識タスクに移転して,追加学習する方式を開発した.また,学習方式を顔画像に基づく個人認証システムに実装し,その有効性を示した.競争的資金
- 二国間交流事業, 2010年, 研究代表者二国間交流「マルチモーダル・マルチタスク個人認証システムの開発」競争的資金
- 日本学術振興会, 科学研究費助成事業 基盤研究(B), 基盤研究(B), 神戸大学, 2007年 - 2008年a) KDA (Kernel Discriminant Analysis)を特徴選択の基準として特徴選択する方式を開発した. b) 特徴空間上のKDA に基づいてパターン認識する方式を開発した.またファジィ識別器の可視化のプリミティブな方式を開発した. c) カーネルファジィ識別器のメンバーシップ関数をSVM のマージン最大化の概念によりチューニングする方式を開発した. d) 相関のある複数のパターン認識問題が逐次的に与えられるマルチタスク学習問題に対し,少ない訓練データで高い汎化能力が得られるマルチプルクラシファイアシステムを開発した.競争的資金
- 日本学術振興会, 科学研究費助成事業 基盤研究(C), 基盤研究(C), 神戸大学, 2006年 - 2007年, 研究代表者複数の学習タスクが逐次的に与えられる問題は,マルチタスク学習と呼ばれる.この学習問題で重要となる能力は,特定タスクで獲得した知識の一部を,それに類似したタスクの学習に利用することで,より少ない学習サンプルで新しいタスクの学習を達成する能力である.これは「知識移転」と呼ばれ,学習タスクおよび学習サンプルが逐次的に与えられる環境では,有効なモデルはまだ提案されていない.本研究では,パターン認識問題への適用を試みるため,新しい学習モデルの構築を行った.2年の研究期間で得られた成果を以下にまとめる. (1)識別器の追加学習,タスク変動の検知,既知・未知タスクの識別,タスク分類,知識転送の機能を有する逐次マルチタスク・パターン認識モデルを開発した.このモデルでは,未知タスクを検知するたびに新しい識別機が自動的に生成される. (2)単一識別器で逐次的に複数タスクを学習できるモデルを開発し,過去に学習したタスクのうち,最も類似度の高いタスクを特定し,その知識を選択的に転送する機能を付加した. (3)機械学習のベンチマークデータを用い,未知タスクに対する上記(1)(2)のモデルの性能を評価した.結果,知識移転機能を導入することにより,高速に提案モデルの汎化能力が向上し,少ない訓練データで高い汎化能力をもつことを示した. (4)パターン認識への適用を行う上で必要となるオンライン特徴抽出アルゴリズムの開発を行った.複数のデータが同時に与えられたとき,それらに対して,一回の計算で固有軸の更新を行える新しい追加学習型主成分分析アルゴリズムを開発した.また,訓練データの中から一次独立となるものを選択し,それを用いて固有空間モデルを更新できる追加学習型カーネル主成分分析アルゴリズムを開発した.競争的資金
- 日本学術振興会, 科学研究費助成事業 基盤研究(B), 基盤研究(B), 神戸大学, 2004年 - 2005年データマイニングによる知識獲得とシステム構築手法の開発サポートベクトルマシン(SVM)をベースにした知識独得とシステム構築法の研究に対して次の成果を得た. 1.静的環境下でのデータマイニングによる知識獲得とシステム構築法の開発 (1)大規模データを領域分割してSVMで高速にかつ高精度にクラスタリングする方法,SVMの集合体により特徴選択を行う方式を開発し,ベンチマークデータで有効性を検証した. (2)静的環境の仮定のもとで,サポートベクトルの候補のみを残して追加学習するSVMのモデルを開発し,ベンチマークデータで有効性を検証した. 2.動的環境下でのデータマイニング手法による知識独得とシステム構築法の開発 (1)動的な特徴空間構成法:追加学習可能な主成分分析(PCA)およびカーネル主成分分析(KPCA)を開発し,ベンチマークデータを用いて,データ分布の変動に追従しながら特徴量選択を行えることを検証した. (2)システム構築法:開発した動的な特徴空間構築法にk近傍法+動的クラスタリングアルゴリズムおよびニューラルネットを組み合わせることで,動的な特徴量選択に追従しながらクラシファイアの追加学習が可能であることを検証した.また,ベンチマークデータだけでなく,顔画像認識にも適用し,その有効性を検証した.但し,当初の目的であった追加学習型SVMへの組み込みは完成に至らず,今後も継続して開発していく予定である. 3.データマイニング手法を用いた画像の領域分割システムの開発 (1)画像の領域分割に適したクラスタリング手法の開発:形状が不確定な物体を撮影した画像から物体領域を抽出・分類するための基盤システムを作成し,たんぱく質結晶画像データベースを用いた結晶領域の検出・判別実験によりその有効性を検証した. (2)画像の領域分割に適した特徴量抽出手法の開発:推移不変ウェーブレット変換を用いた多重スペクトルヒストグラムの構成法を提案し,画像の多重スペクトルヒストグラム特徴をもとにした類似画像検索実験を行い,特徴量として領域分割への応用の可能性を検証した.
- 日本学術振興会, 科学研究費助成事業 基盤研究(C), 基盤研究(C), 神戸大学, 2004年 - 2005年追加学習可能なパターン認識システムの提案と顔画像認識への応用追加学習可能なパターン認識システムの開発に必要不可欠な学習アルゴリズムを考案した.成果の概要を以下にまとめる. (1)特徴空間の追加学習として,従来のIncremental Principal Component Analysis (IPCA)の改良を行った.具体的には,特徴空間の次元増加の判定基準として,寄与率による方法を提案し,その更新式を求めた. (2)従来のIPCAは,1つデータが与えられるたびに固有値問題を解く必要があった.これに対し,複数のデータをまとめて1回の更新で新しい固有基底を求める学習アルゴリズム(Chunk IPCA)を提案した. (3)改良IPCAアルゴリズムおよびCIPCAアルゴリズムを顔画像認識に適用し,追加学習が進むにつれて,認識精度が高まることとFalse Positive Rateが小さくなることを確認した.また,CIPCAを導入することによって,学習時間が大幅に短縮されることを確認した. (4)特徴空間の更新に伴い,識別機(ニューラルネット)の更新も同時に行う必要があり,結合荷重の更新だけでなく,入力変数の個数の変動にも追従できなければいけない.この問題に対し,長期記憶を導入したニューラルネットの記憶アイテムを特徴空間に合わせて更新し,それらを訓練データと一緒に学習するアルゴリズムを開発した. (5)従来の独立成分分析(Independent Component Analysis ; ICA)を教師あり学習に拡張する方式を提案し,独立性とクラス分離性を同時に高める学習アルゴリズムを導出した.また,いくつかのベンチマークデータで性能評価を行い,従来のICAやPCAで求めた特徴量に比べて,性能がよいデータもあることを確認した.
- 日本学術振興会, 科学研究費助成事業 基盤研究(B), 基盤研究(B), 2003年 - 2004年表面筋電図による運動単位の活動可視化に関する研究本研究では,表面筋電図からの運動単位の分離とその活動の可視化のため,以下のように研究を実施した. 1.運動単位の分離手法の改良 統計モデルの導入が容易な過完備基底を用いた分離手法の検討を行った.本手法を実計測データに対して適用し,ブラインドデコンボリューションと同等の分離性能を持つことを確認した.また,観測チャンネル数が,運動単位数よりも少ない場合であっても,計測条件に依存するものの,それぞれの運動単位に分離できる可能性があることを確認した. 2.統計モデルを利用した分離手法の有効性の検討 boosting機構に対してKDAを利用した認識システムの検討を行い,SVMなどの既存の手法と変わらない識別性能が得られることを確認した.また一般的に,汎化能力を持たせるためには,クロスバリデーションのような多大な時間を要するパラメータ選択を行うが、それに変わる簡便な指標を考案し,計算コストをほとんどかけずに適切なパラメータ選択が可能であることを示した. 3.分離された運動単位の活動の3次元時系列位置推定 有限要素法を用い,分離された個々の運動単位に由来する皮膚表面上の電位より,運動単位の脱分極位置の3次元位置推定を行った.これにより,運動単位を構成する筋線維の3次元位置および,その時間変化を推定できることを確認した.また,電流強度の時間変化を追うことが可能となり,神経支配帯の大きさの推計が可能であることが明らかになった.また,これらによって,表面筋電図を計測する多チャンネル電極が満たすべき仕様を明らかにした. なお本研究は,平成15年度に神戸大学工学部小谷学助教授を研究代表者として進められたものであるが,平成16年5月に小谷先生が急逝されたため,急遽代表者の交代を行った.小谷先生の貢献は上記成果全般に渡っていることをここに記す.
- 日本学術振興会, 科学研究費助成事業 基盤研究(B), 基盤研究(B), 神戸大学, 2002年 - 2003年マルチクラスサポートベクトルマシンの開発と診断,画像処理への応用分離不能領域を持つ等のサポートベクトルマシンの問題を解決して大規模なパターン認識問題に適用できるサポートベクトルマシンの開発と診断,画像処理への応用の研究を進め,以下の成果を得た. 1.マルチクラスサポートベクトルマシンの開発 ・サポートベクトルマシンにファジィ論理を導入して分離不可能な領域のないファジィサポートベクトルマシンのアーキテクチャとそのソフトウエアを開発した. ・決定木方式のサポートベクトルマシンおよびペアワイズサポートベクトルマシンでは,分離不能領域は存在しないが,学習順序により認識性能が変わる.このため最適な学習順序を決定する方式と,そのソフトウエアを開発した. 2.サポートベクトルマシンの高速学習方式の開発 ・データを数十個同時に最急上昇法により解を求めることにより多クラス問題および関数近似用サポートベクトルマシンを学習する方式と,そのソフトウエアを開発した. 3.中,大規模学習データでの評価 ・実データにマルチクラスサポートベグトルマシンを適用して従来のサポートベクトルマシンよりも認識性能および学習時間が短縮することを検証した. 4.設備診断への適用 ・設備診断への適用として,まずサポートベクトルマシンの識別能力を最大化する特徴抽出法について検討を行った.特徴抽出に独立成分分析を用いた結果,配管からの漏洩音や数字パターン,ベンチマークデータ等に対して有効な特徴が得られることを示した.また,マージン最大化に基づく進化的特徴抽出方法の開発も行い,その有効生を確認した. 5.画像処理への適用 ・サポートベクトルマシンに入力する特徴抽出方法として,ウェーブレット変換による多重解像度解析手法の有効性を検証した.ウェーブレット変換により圧縮抽出された特徴パターンを用いた類似画像検索システムを構築し,情景画像,テクスチャ画像などの細密な濃度変化を持つ画像を用いて実験を行った結果,良好な画像検索結果が得られることを示した.また,サポートベクトルマシンを用いたたんぱく質結晶状態の識別のための特徴量抽出手法を開発し,その有効性を確認した.
- 日本学術振興会, 科学研究費助成事業 若手研究(B), 若手研究(B), 神戸大学, 2002年 - 2003年長期記憶を導入したニューラルネットモデルの提案と動的環境におけるロバスト性の検証ダイナミックに変化する環境の下では,過去に得た知識が常に有効であるとは限らず,環境に適応するため絶えず修正を要求される.しかし,同じ環境が将来において再び現れるようなケースでは,過去に獲得したすべての知識を修正するのは必ずしも効率的とはいえない.つまり,ある時点で通用しなくなった知識であっても,長期的な記憶として保存し,その知識が有用となる環境が再び現れたときに想起・利用できるようなメカニズムをもつことが望ましい.また,学習期間に終わりのないlife-long学習としての性質をもつには,知識を効率よくメモリに蓄積できなければならない. 本研究では,上記のような機能を有するニューラルネットモデルを提案した.このモデルは,(1)入出力関係を学習するニューラルネット部,(2)ニューラルネット部で抽出された知識を蓄える連想バッファ,(3)連想バッファにある知識のうち必要なものを長期的に保持するための長期記憶,(4)環境の変動を検知する検知部の4つのモジュールで構成される. 平成14年度において提案したモデルでは,ロバストな環境変動の検知を行うためのメカニズムと高速な環境への適用を実現するための連想メカニズムを開発し,この機能を実装した.複数の異なる一次元関数が順次移り変わっていく単純な動的環境の下で提案モデルの適応能力をシミュレーション実験で調べた.その結果,提案したモデルは環境変動を正確に検知し,過去に経験した環境の知識を活かして,高速に環境に追従できることを確認した.また,動的環境の下であっても追加学習を安定に行えることを示した. 平成15年度では,移り変わっていく個々の環境に特有の知識と不変な知識を区別して,共有知識を抽出・利用する知識移転のメカニズムを付加した.シミュレーション実験を通して,この知識転移の機能が正しく機能し,さらに高速な環境適応が可能となることを確認した.
- 日本学術振興会, 科学研究費助成事業 基盤研究(B), 基盤研究(B), 神戸大学, 2001年 - 2003年動的環境に適応できる知的音響診断システムの開発本研究では動的な環境に適応できる能力を持つ音響診断システムの開発を目的としている.具体的には,環境が変わったことによって未知の音が発生したときに,未知の音であることを認識すると共に,既に構築したモジュールを変更することなくその未知の音を正確に診断できる新たなモジュールを付加していくような「診断ネットワーク」を新たに提案し,配管からのガス漏洩音の検出を対象としてその診断能力を詳細に評価した.さらに,安定した診断を行うために,音響信号の特徴抽出方法に遺伝アルゴリズムや独立成分分析などの適用を検討・評価した.さらに,カーネル法による識別方法の適用可能性を評価した. ○診断ネットワークの提案と評価 来年度実施予定の長期間(1年程度の間,適当なサンプリング間隔で)のデータ収集時に使用する複数のマイクによる複数の環境に対する同時データ収集装置を購入し,その性能を評価した. ○漏洩音の特徴抽出 特徴抽出方法として,進化的な特徴抽出方法や独立成分分析による抽出方法を検討した.数字パターンや評価用のデータベースなどに対する評価や石油精製プラントで収集したガス漏洩音などに適用して評価したところ,良好な結果が得られた. ○カーネル法による識別方法 良好な汎化能力が得られることが期待できるカーネル法やマージン最大化などを用いた識別方法を遺伝子発現データなどに対して評価したところ,有効であることが示された. ○ブラインドデコンボリューション 複数マイクから種々の特徴を分離するためには,音響信号のブラインドデコンボリューションが必要であるので,その基礎的な検討を生体信号に対して行った.得られた結果より,開発したアルゴリズムは有効であることが示された.
- 日本学術振興会, 科学研究費助成事業 基盤研究(C), 基盤研究(C), 神戸大学, 2001年 - 2002年独立成分分析による信号処理に関する研究独立成分分析とは,統計的に独立な信号が混合した観測信号から,元の独立な信号を推定しようとするものである.最近ニューラルネットワークの分野で,この独立成分分析に関する学習アルゴリズムがいくつか提案されている.また,その応用分野として,音声・画像や生体信号処理などのブラインド信号分離でその有効性が示されている. しかし,このような独立成分分析をパターン認識の特徴抽出に適用する場合,どのような特徴が抽出されているのかについては明確でない.そこで,文字画像や音響信号などに独立成分分析を適用することによって,下記の2点について検討する. 1.どのような基底関数が形成されるのか 2.元の信号のどのような特徴が抽出されているのか さらに,文字認識や音声認識などのパターン認識を対象として,主成分分析などを用いた場合と認識率で比較して,独立成分によって抽出された特徴の有効性について定量的に評価する. 上記の研究内容によって,独立成分分析のパターン認識への適用可能性を検討し,その特質を定量的に評価することが本研究の目的である. そこで,本研究では一般的な手書き数字パターンと,設備機器の音響診断データを対象として独立成分分析法を適用し,パターンの認識率を尺度にして,定量的に独立成分分析法の有効性を検討した.さらに,教師付き独立成分を用いた認識方法を提案し,その有効性を評価した. また,独立成分分析を用いた生体信号処理として筋電図のブラインド・デコンボリュージョンに適用し,運動単位の推定の可能性を検討した.
- 日本学術振興会, 科学研究費助成事業 基盤研究(C), 基盤研究(C), 神戸大学, 1998年 - 1999年携帯型音響診断システムの開発音響診断技術の実用化を目指して本研究では未知の音を誤って診断したときに、既に学習したネットワークを変更することなく、誤診断した音を正確に診断できる新たなネットワークを付加していくようなモジュール構造の「診断ネットワーク」を新たに提案すると共に、携帯型の診断装置を製作した。そして、配管からの漏洩検出を対象として、その診断能力を詳細に評価するために、下記の事項について検討した。 1.長期間に渡る正常音と異常音の収集 診断方法の詳細な評価には、より多くの正常音や異常音を収集する必要がある。そこで、石油精製プラントにおける種々の暗騒音のもとで配管からのガス漏れ音の異常音を収集した。同時に、このような異常のない状態の正常音(暗騒音)も固定したマイクによって長期間にわたって大量に収集した。 2.診断ネットワークの構築 モジュール構造の診断ネットワークを用いて,長期間に渡るデータに対する診断ネットワークの動作を確認した。また、診断ネットワークの汎化能力の向上を目指して、遺伝アルゴリズムを用いたニューラルネットワークの構造選択や、特徴抽出に関する基礎的な検討も行った。さらに,独立成分分析を漏洩音の特徴抽出に適用し,その有効性を確認した。 3.携帯型の診断装置の製作 ノート・パソコンにマイクロフォンからの音響データを直接入力し、周波数分析から診断までを行う携帯型の診断装置を開発した。この装置は、音響データを入力するインターフェイスと高速フーリエ変換などの前処理、診断ネットワークの機能をノート・パソコン上で実現している。これにより、リアルタイムな診断が可能となった。
- 日本学術振興会, 科学研究費助成事業 奨励研究(A), 奨励研究(A), 大阪教育大学, 1998年 - 1999年モジュール構造ニューラルネットの機能形成モデルとヘルスモニタリングへの応用構造物の健全度を非破壊で調べるヘルスモニタリングの基本技術として,ウェーブレット解析と階層型ニューラルネットのハイブリッド化手法を提案した。ウェーブレット解析は観測信号(構造物の加速度や速度情報)から正常/異常の判断に用いる特徴量の抽出に利用され,ニューラルネットは構造物の劣化を推定するのに用いられる。構造物を3自由度ダイナミカルシステムで近似し,観測信号から解析的に解が求まらない設定のもとで,バネ定数および減衰定数の劣化の程度を推定する問題に提案したハイブリッド手法を適用した。計算機シミュレーションによって推定精度を調べた結果,バネ定数はある程度の精度で推定可能であったが,減衰定数については十分な推定精度が得られなかった.ここで用いたニューラルネットはモジュール構造をもたないものであるが,この代わりに創発的に機能獲得が可能なモジュール構造ニューラルネットを適用することで,前述の問題を改善できる可能性がある.そこで,まずニューラルネットの基本特性を調べる際によく取り上げられる連想記憶の問題を取り上げ,モジュール構造ニューラルネットの有効性を検討した.モジュール構造を決定するパラメータの探索に遺伝的アルゴリズムを用い,所望の特性に適合したモジュール構造(各モジュールは異なる機能をもつ)が自動的に決定されるニューラルシステムを開発した。シミュレーション実験の結果,試行錯誤では発見の難い高性能なモジュール構造の探索が,本システムで可能になることを確認した.最終的には,これをヘルスモニタリングに適用して性能が改善されることを確認する必要がある.しかし,本研究期間内では残念ながらこれを達成できなかった.今後の研究課題としたい.また,特徴抽出手法として,ウェーブレット解析の代わりに最近ブラインド信号分離問題で盛んに研究されている独立成分分析の適用も検討したことを付記しておく.
- 日本学術振興会, 科学研究費助成事業 奨励研究(A), 奨励研究(A), 大阪教育大学, 1993年 - 1993年モジュール型神経回路網モデルの動的性質に関する定量的評価モジュール型神経回路網モデルとして、対称結合をもつ相互結合型神経回路網を複数個結合したものを取り上げた。このようなモデルにおける各モジュールの活性ダイナミクスとモジュール間の結合ダイナミクスは、ネットワーク全体のエネルギー関数を定義することで与えらる。 本年度の研究は、このようなモデルの連想記憶能力をシミュレーション実験で定量的に評価することを目的とした。記銘するパターンとしては、各ビットが2値(±1)であるランダムベクトルを用い、総ニューロン数に対するパターン数(記憶率:r)で評価した。その結果、モジュール構造をもたない従来のホップフィールドネットに比べ、モジュール数が多すぎなければ、飛躍的に連想能力が向上することがわかった。例えば、総ニューロン数が500、モジュール数が2のとき、r=0.5で限界方向余弦d_C≒0.5、r=1.0でd_C≒0.7となった(ホップフィールドネットの場合、r≒0.2でd_C≒1.0となる)。さらに、与えられた問題に対して最適なモジュール数が存在し、それを越えると急速に連想能力が劣化する現象が見られた。この原因についての詳しい考察は、今後の課題とする。 また、ここで用いたモジュール型神経回路網には、モジュールの状態間に多対多の関係がある場合でもうまく動作するような機能を付加している。これは、2つのモジュール間の相互作用を決定する階層型ネットワーク(インターネット)に両モジュールの状態を入力することで実現している。本研究では、この機能がうまく動作することも、多対多関係をもつ文字パターン対を使った実験により確認している。
- 日本学術振興会, 科学研究費助成事業 試験研究(B), 試験研究(B), 奈良工業高等専門学校, 1990年 - 1991年印影の品質評価機能を有する高性能自動印鑑照合システムの開発本研究は、研究代表者らが従来行ってきた自動印鑑照合方式の研究成果を基にして、熟練者と同程度の真偽判別性能を有し、印影品質の変動に対しても熟練者と同様に柔軟に適応できる自動印鑑照合方式を開発することを目的としている。平成2年度から2年間にわたり、当初の研究計画に基づき研究を行い、所期の目的をほぼ達成することができた。以下に本研究によって得られた新たな知見、成果の概要について述べる。 1.被照合印影各部の品質(印影文字線と背景のコントラストが十分な良品質部分、文字線の不鮮明な不良品質部分)を機械的に識別する方法を開発した。本方法は、印影の部分画像の濃度ヒストグラムの形に基づいて品質識別を行うものである。種々の実印影画像を用いて識別実験を行い、本手法は熟練者の主観評価の結果とほぼ一致する結果を与えることを確認した。 2.既開発の正規化距離法による自動印鑑照合方式に、本研究で開発した品質識別法を組み込み、被照合印影の良品質部分のみを照合対象とする、いわゆる品質評価機能を有する自動印鑑照合方式のシミュレ-ション・システムを開発した。そして種々の品質変動を含む印影デ-タを用いて、照合実験を行い、熟練者による結果と比較検討した。その結果、本照合方式は熟練者と同程度の真偽判別性能および品質変動への適応性があることが確認された。ただし、不良品質部分が全体の50%を越えた場合の処理法を更に検討する必要がある。 3.本研究で開発した自動印鑑照合方式を、パ-ソナルコンピュ-タと高速画像処理ボ-ドからなる小型システムにインプリメントし、実用的な小型印鑑照合装置のプロトタイプを構築し、その性能評価を行った。その結果、処理速度の向上について更に検討する必要があることが明らかになった。
研究シーズ
■ 研究シーズ- AI×ビッグデータ解析シーズカテゴリ:情報通信研究キーワード:機械学習, ビッグデータ解析, 社会実装, セキュリティ, プライバシー保護研究の背景と目的:様々な情報がデジタル化される現代において、大量のデータ、つまりビッグデータを解析して価値に転換することが重要です。本研究室では、AI技術を駆使し、データから価値を生み出すための研究を行うとともに、ユーザの情報資産を狙うサイバー攻撃を検知・監視するAI技術を開発しています。研究内容:機械学習や深層学習に代表されるAI技術をサイバーセキュリティやプライバシー保護などに応用し、サイバー空間と物理空間における人々の安全安心を担保する技術を開発しています。また、AI技術を画像、音声、テキスト、センサーデータ、ログ情報など、大量かつ高次元のビッグデータ解析に応用し、識別、予測、診断、異常検知、可視化などを高精度に行う技術を開発するとともに、社会実装に資するAI技術の開発を目指しています。
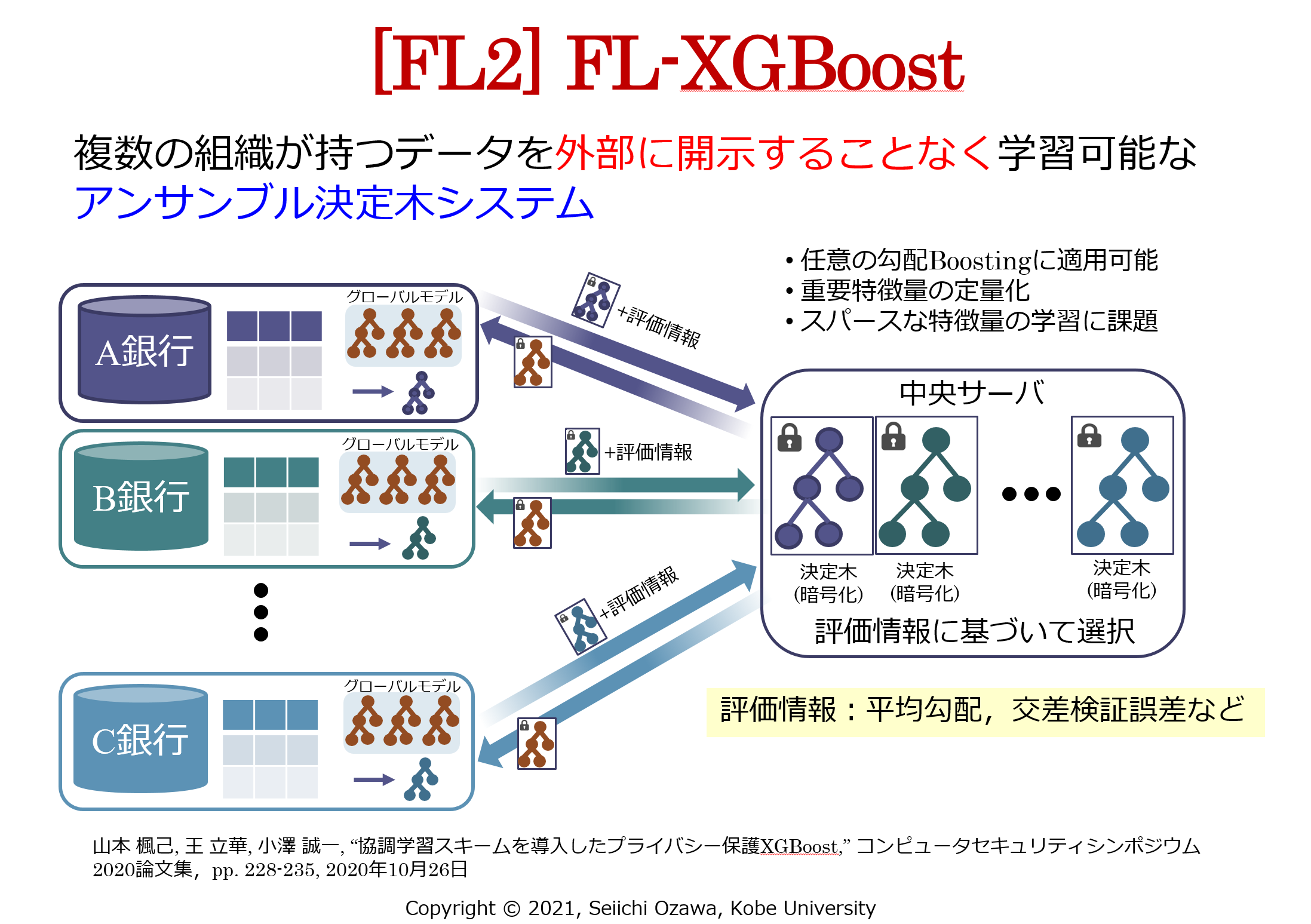 期待される効果や応用分野:・データから価値を生み出すAI技術 ・サイバー空間における安全安心を担保するAI技術 ・AIそのものの安全性を保障する技術 をメインテーマとし、様々な応用分野のデータ解析を行っています。関係する業績:①小澤、齋藤:「データサイエンスの考え方: 社会に役立つAI×データ活用のために」オーム社, 2021 ②齋藤、小澤、羽森、南:「データサイエンス基礎」培風館、2021
期待される効果や応用分野:・データから価値を生み出すAI技術 ・サイバー空間における安全安心を担保するAI技術 ・AIそのものの安全性を保障する技術 をメインテーマとし、様々な応用分野のデータ解析を行っています。関係する業績:①小澤、齋藤:「データサイエンスの考え方: 社会に役立つAI×データ活用のために」オーム社, 2021 ②齋藤、小澤、羽森、南:「データサイエンス基礎」培風館、2021
ozawasei kobe-u.ac.jp ※左記の「@」は画像ですので、ご利用の際はテキストの「@」を入力してください。
kobe-u.ac.jp ※左記の「@」は画像ですので、ご利用の際はテキストの「@」を入力してください。
kobe-u.ac.jp ※左記の「@」は画像ですので、ご利用の際はテキストの「@」を入力してください。